What do we want to optimize for? Most of the businesses fail to answer this simple question.
Every business problem is a little different, and it should be optimized differently.
We all have created classification models. A lot of time we try to increase evaluate our models on accuracy. But do we really want accuracy as a metric of our model performance?
What if we are predicting the number of asteroids that will hit the earth.
Just say zero all the time. And you will be 99% accurate. My model can be reasonably accurate, but not at all valuable. What should we do in such cases?
Designing a Data Science project is much more important than the modeling itself.
This post is about various evaluation metrics and how and when to use them.
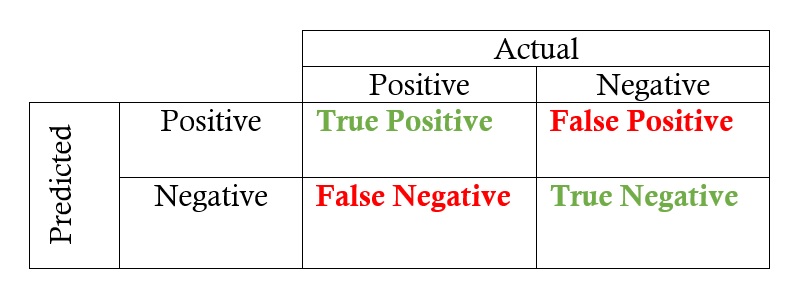
A. Accuracy
Accuracy is the quintessential classification metric. It is pretty easy to understand. And easily suited for binary as well as a multiclass classification problem.
Accuracy = (TP+TN)/(TP+FP+FN+TN)
Accuracy is the proportion of true results among the total number of cases examined.
To continue reading this article, click here.



What is the percentage of accuracy? snow rider 3d
This article is very amazing! The content is very much useful…. Official Website