Rich Lanza will present Using Letter Analytic Techniques to Pinpoint Textual Deviations at the Text Analytics World Conference, taking place June 21-22 in Chicago. For more information about the event and to register, click here. Use code PATIMES16 for 15 percent off of your registration.
I feel that textual analytics always produces something interesting yet the tools being used can take too long or outright miss the subtleties in the data. Wordles, for example, provide a useful image of the words yet are not effective in identifying deviations over time or to expected language benchmarks. To supplement this need, a new letter approach, as outlined in this blog and a new research brief, is explained more fully. Using the letters versus words approach, the analyst can make more effective use of their time while performing a more complete deviation analysis of the text at hand. Therefore quality and efficiency is increased but first off, let’s understand more about the use of the common Wordle and why I love and hate them all at once.
Shakespeare’s Worldes
Wordles are otherwise called “word clouds” and are images that show a greater prominence of words appearing more frequently in the source text. For example, below (Image 1) is every tragedy play written by William Shakespeare with words having the highest frequency also having the largest image:

Comparing Tragedy to Comedy Plays With Wordles
To understand how comparisons can be made between Wordles, let’s now look at the collection of Shakespeare’s comedy plays (17,882 words) as summarized in another 150 to 200 words below (Image 2). As you scroll back above (Image 1) and then to this image, can you see the differences?

In your analysis you will most likely realize quickly that:
So, you may ask yourself how can a Wordle chart be so appealing and also be so flawed in its design? To understand this, we must first realize that a Wordle is meant to focus on the top occurring words as our screens were not built large enough to handle the magnitude of thousands of words. Also, in both the comedy and tragedy plays, roughly half of the words appear only once in each play and we can quickly realize that one occurrence is no comparative match to the word “the” which appeared 7,604 and 10,920 times in tragedy and comedy plays, respectively.
Now, assume we removed the top 25 words (making up 30% of word occurrences) as seen below for both tragedy (Image 3) and comedy (Image 4) plays:


A Newfound Comparative Approach Using Letter Analytics
First, we should back up to how we were able to get the data for analysis. The texts were obtained from the MIT web presence of Shakespeare’s 37 plays and sonnets (http://shakespeare.mit.edu/). With some help from an experienced data scientist (James Patounas from Source One Management Services, LLC) and his skills in using Python software, we were able to quickly web scrape the text data on the MIT pages and organize all 37 plays for analysis.
The dashboard image below (Image 5), a vast improvement over a Wordle, presents all 37 plays across the categories of tragedy, comedy and now, history. Instead of making word pictures, the dashboard focuses on letter bars and more specifically, the first two letters of each word. Thus, a different chart of each two-letters was developed for each of the 26 letters (Image 6 below is an example of the letter K in isolation). That amounts to 702 two-letter combinations (AA to ZZ) that then fit within the frame of 26 single letters (A to Z). Unlike the Wordle that could not represent the word changes between the play types, the letter analytic dashboard can do so and be able to present the results in one screen.
Isolation of each letter before further analyzing the two letter combinations led to an ability to detect deviations in lower occurring letters (i.e., letter X), rather than having high occurrence letters (i.e., the letter T related to the word “the”) dilute the analysis in the dashboard. In essence, if there are 14,528 unique tragedy play words, 17,882 unique words in comedy plays or 100,000 unique words in a data set of your choice, all are reduced down to the 702 x 26 frame of letters for improved review.
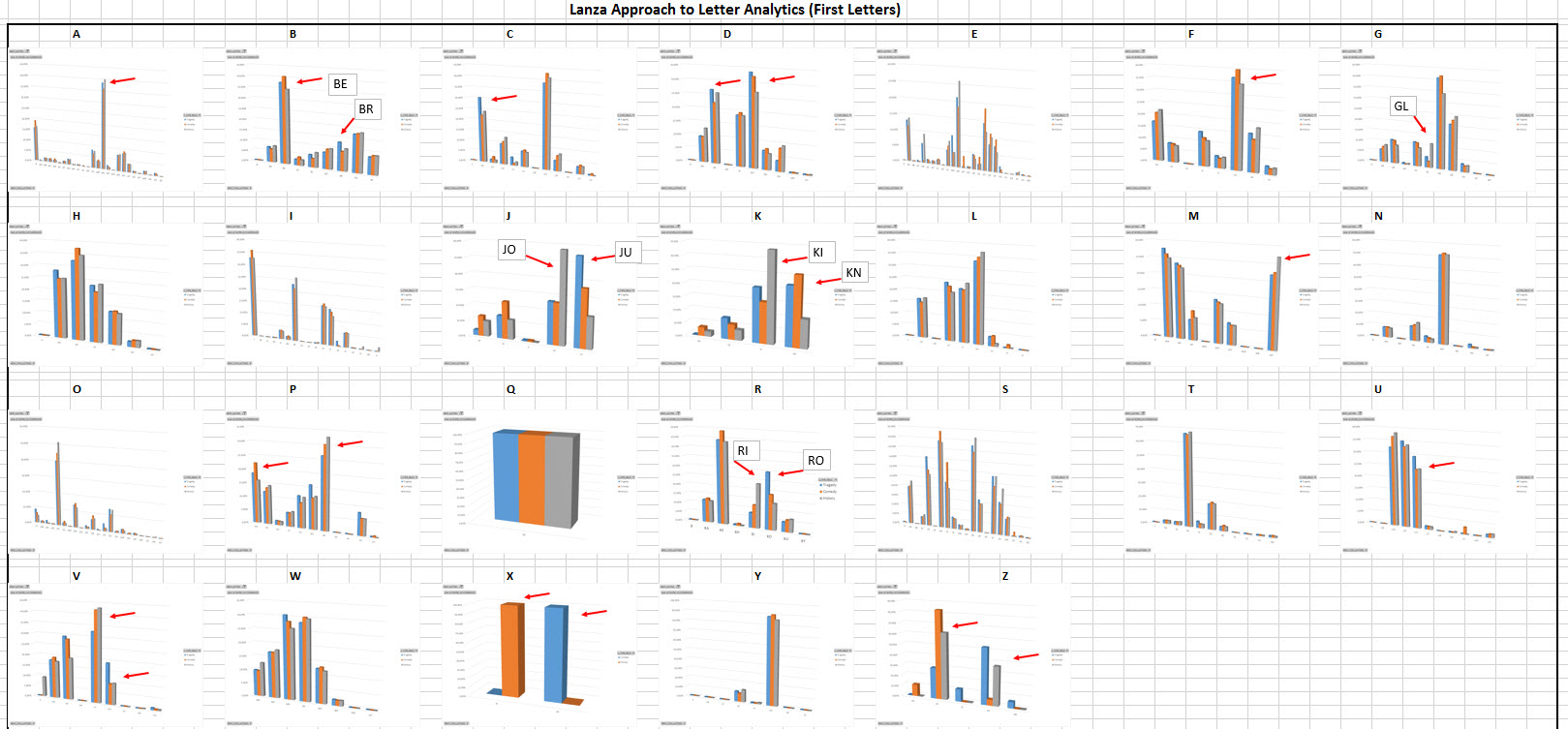
Using this approach, entitled the “Lanza Approach to Letter AnalyticsTM (“LALA”), there are only 23 visual differences leading to only 3% of the 702 two-letter combinations (see red arrows denoted in Image 5) having noticeable visual change. Some noticeable variances were due to names of people or places in the plays such as “JU” for Juliet, “RO” for Romeo, “BR” for Brutus”, “RI” for Richard or “GL” for Gloucester.
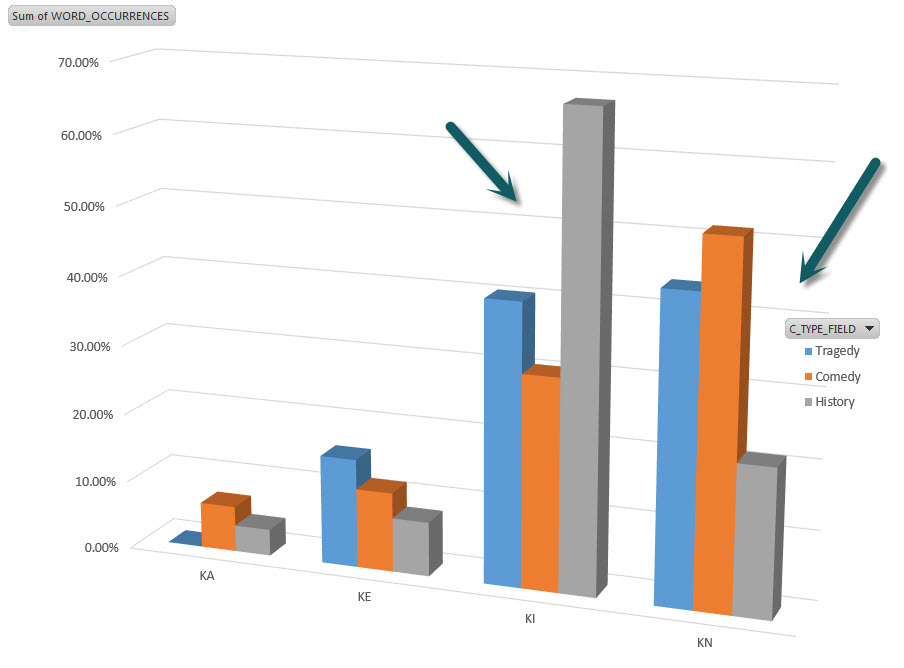
For something a little more interesting, the word “king” appeared in many forms (king, kings, kingdom, etc.) in the 10 history plays at 2,186 times given their high occurrence of plays centered around various kings. The word “king” represented 0.3% of the total number of roughly 825,000 word occurrences in all of Shakespeare’s plays yet, as can be seen below (Image 6), it is a noticeable 25% deviation for the letter K in the first-two letter combination of “KI”. Also as seen from the below image (Image 6), the deviation of KN for history plays is due mainly to a drop in all forms of the word “know” which appeared more frequently in tragedy and comedy plays, where there is more discussion around what people know and therefore, their own introspection.
 Rich Lanza CPA, CFE, CGMA (www.richlanza.com) has nearly 25 years of fraud detection, cost recovery and audit experience specializing in data analytics, while becoming a leading authority in these areas. Rich wrote over 19 publications, educational training videos, and over 75 articles on the practical use of technology in an audit setting. Rich has been awarded by the Association of Certified Fraud Examiners for his research on proactive fraud reporting. Rich recently discovered a new analysis technique entitled letter analytics to speed results within textual analysis. He is also a regular presenter for the Association of Certified Fraud Examiners, Auditnet®, Basware, CFO.com, the Institute of Internal Auditors, and Lorman Financial. Rich has worked for organizations ranging in size of $30 million to $100 billion and in all, has helped them find value/cash savings through the use of technology and recovery auditing.
Rich Lanza CPA, CFE, CGMA (www.richlanza.com) has nearly 25 years of fraud detection, cost recovery and audit experience specializing in data analytics, while becoming a leading authority in these areas. Rich wrote over 19 publications, educational training videos, and over 75 articles on the practical use of technology in an audit setting. Rich has been awarded by the Association of Certified Fraud Examiners for his research on proactive fraud reporting. Rich recently discovered a new analysis technique entitled letter analytics to speed results within textual analysis. He is also a regular presenter for the Association of Certified Fraud Examiners, Auditnet®, Basware, CFO.com, the Institute of Internal Auditors, and Lorman Financial. Rich has worked for organizations ranging in size of $30 million to $100 billion and in all, has helped them find value/cash savings through the use of technology and recovery auditing.


