Customer Retention models are arguably the most valuable models that organizations can develop in improving overall customer profitability. The ability to target high value customers who are most likely to defect or become inactive allows organizations to prioritize limited resources within an overall retention strategy. With customers now scored in terms of their value and defection risk, testing can be now employed across different groups or segments of customers as we attempt to find whether or not save rates differ across these groups.
In most cases, we know that save rates will vary, hence the need for net lift modelling. The concept here is to develop targeting or predictive analytics tools that not only target who is most likely to defect but also whether or not we can save them. Net lift and the approach in creating these tools have been discussed as popular themes at many Predictive Analytics Conferences. What has not been discussed at great length is the actual concept of retention. Retention is a nebulous term and defining it can vary drastically from organization to organization. Customer retention as a definition would be an easy exercise if we relied on the customer to actually indicate no longer being a customer.
Examples of this include renewal-based programs where I have to renew my subscription, my policy or membership in a particular program. But this type of active-based retention only represents a small portion of retention activity for most organizations. Most retention activity is passive in the sense that the customer does not tell us that he or she is leaving. The company has to deduce customer retention based on customer activity within a certain period of time. But that is the dilemma. What is the period of time and how do we go about determining it? Simple frequency distribution reports could be produced that yield purchase activity within different time intervals. Listed below are some industry type examples.
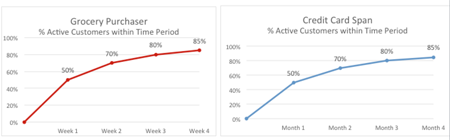
For the grocery company, the following report looks at customer activity of active customers by week while for a credit card company, the interval is at the monthly level. Based on these two examples, it appears that 70% of active customers exhibit repeat activity within a two week period while in the case of the credit card company, 70% of active customers exhibit repeat activity within a two month period. Meanwhile in the example of tire purchases, we see the following:
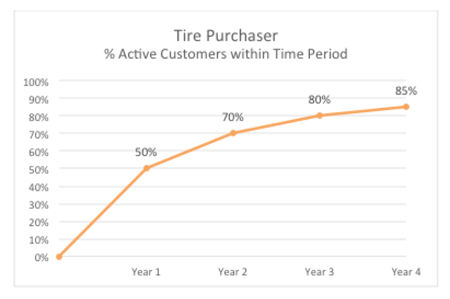
Here in this example, 70% of active customers exhibit repeat activity within a two year period. You will note that we have used 70% in all three cases. Why? In each of these reports , we attempt to find the point where the purchase rate begins to flatten which some analysts refer to as the elbow point. Using the information from these three reports, we might surmise that the retention period for these three companies might be defined as follows:
However, in other industries where purchase behavior is highly infrequent, analysis of purchase behavior frequency distributions is not really relevant. This is where the so-called “art of data mining” can be employed. Let’s take at look an example of trying to identify retention of automobile customers. Here the so-called purchase cycle is not every few weeks or few months but arguably five years. Certainly one could develop programs that are geared towards the end of the five year period when the customer is potentially considering the purchase of a new vehicle. But the concept of retention could be considered a distant reality as it has been five years since the last purchase. The challenge here is to identify shorter-term type behaviour that could be used as a proxy for customer retention. Many customers have leasing type arrangements or warranty service type arrangements which typically involve the customer to engage with the company on at least an annual basis if not sooner. Although the predictive model itself might not be identifying the likelihood of repurchase, instead we are developing the likelihood of some level of customer engagement which is occurring within a 12 month period. Marketers recognize that the ability to optimize customer engagement through these shorter type activities does help promote the longer term retention behavior of repurchasing a car.
Building predictive models for retention is certainly not a straightforward process. The literature continues to stress the need for not only the data science technical and mathematical skills but also the need for business acumen or at least the appetite of the data scientist to acquire more knowledge about the business. Retention models represent a classic example of this need where retention behavior will differ between industries and in some cases between businesses. Clearly, the best retention solutions will be developed by those practitioners who aspire to that hybrid role of being both business savvy alongside their deep technical data science skills.
Richard Boire, B.Sc. (McGill), MBA (Concordia), is the founding partner at the Boire Filler Group, a nationally recognized expert in the database and data analytical industry and is among the top experts in this field in Canada, with unique expertise and background experience.
Mr. Boire’s mathematical and technical expertise is complimented by experience working at and with clients who work in the B2C and B2B environments. He previously worked at and with Clients such as: Reader’s Digest, American Express, Loyalty Group, and Petro-Canada among many to establish his top notch credentials.
After 12 years of progressive data mining and analytical experience, Mr. Boire established his own consulting company – Boire Direct Marketing in 1994. He writes numerous articles for industry publications, is a well-sought after speaker on data mining, and works closely with the Canadian Marketing Association on a number of areas including Education and the Database and Technology councils. He is currently the Chair of Predictive Analytics World Toronto.


