
Originally published in tech-at-instacart
Key contributors: Sharath Rao Karikurve, Jagannath Putrevu, Haixun Wang, Allan Stewart and Weian Sheng
Imagine this: You’re at home, preparing to rely on Instacart for your grocery delivery. You’ve carefully chosen each item, but then you’re notified that some products might not be in stock at the store. That’s where Instacart’s machine learning model steps in, facing the challenge of accurately predicting suitable replacements that match your preferences. This blog post will explore the complex challenges Instacart overcomes in building a robust replacement recommendation model and the innovative solutions implemented to ensure smooth and satisfactory replacements.
The replacement recommendation model sits at the heart of the replacement experience for our customers and shoppers. In a previous post, The Story Behind an Instacart Order, we provided a sneak peek into this model and how our customers engage with it when placing orders. In this blog post, we intend to delve deeper into the machine-learning aspects of the replacement model, shedding light on the various decisions we made throughout its development.
One of Instacart’s key challenges is predicting product availability without real-time inventory data. Our machine-learning model prompts replacement suggestions if a product appears unavailable when an Instacart customer shops. This replacement model also assists Instacart shoppers in selecting the best replacements during their shopping trips. Refer to Figure 1 for an example of how replacement recommendations are displayed within our product interface.
Head vs Tail Problem: Popular products, often receiving substantial customer engagement, are easier to rank due to abundant data. However, we primarily depend on catalog attributes to recommend effective replacements for less frequently purchased (tail) items or newly introduced products (cold start). This approach might only sometimes result in high customer approval. Ensuring a balance between these extremes is crucial for customer satisfaction.
Optimizing for Retailer-Specific Inventory: Using a uniform model across various retailers can introduce biases and reduce relevance. Tailoring replacements to consider each retailer’s unique stock and customer preferences enhances the accuracy and satisfaction of recommendations.
Availability and Ranking Dilemma: A significant challenge arises when top-ranked replacements are also out of stock, necessitating the need for lower-ranked items to serve as effective alternatives. These options must still be well-aligned with customer expectations.
Diverse User Preferences: Customer preferences are highly nuanced and specific, often involving unique needs across various product attributes such as size, flavor, and brand. Meeting these complex expectations is challenging but essential to avoid dissatisfaction. Understanding and accurately matching these multilayered preferences are crucial to delivering effective product replacements.
The primary aim of the replacement model is to suggest suitable substitutes for out-of-stock products that closely match the original product and align with customer preferences, thereby enhancing customer satisfaction. In this blog, we will focus on the user-agnostic subsystem of our replacement model, which is one part of the more extensive replacement system. This critical subsystem allows us to cater to a broad demographic by leveraging general replacement patterns for Instacart customers. Figure 2 provides an overview of the machine learning models that generate user-agnostic product recommendations. While this post highlights these foundational methodologies for delivering broad recommendations, the system’s true strength lies in its ability to adapt and refine through advanced mechanisms like personalization, cart context, etc. — topics we will explore in future blog posts.
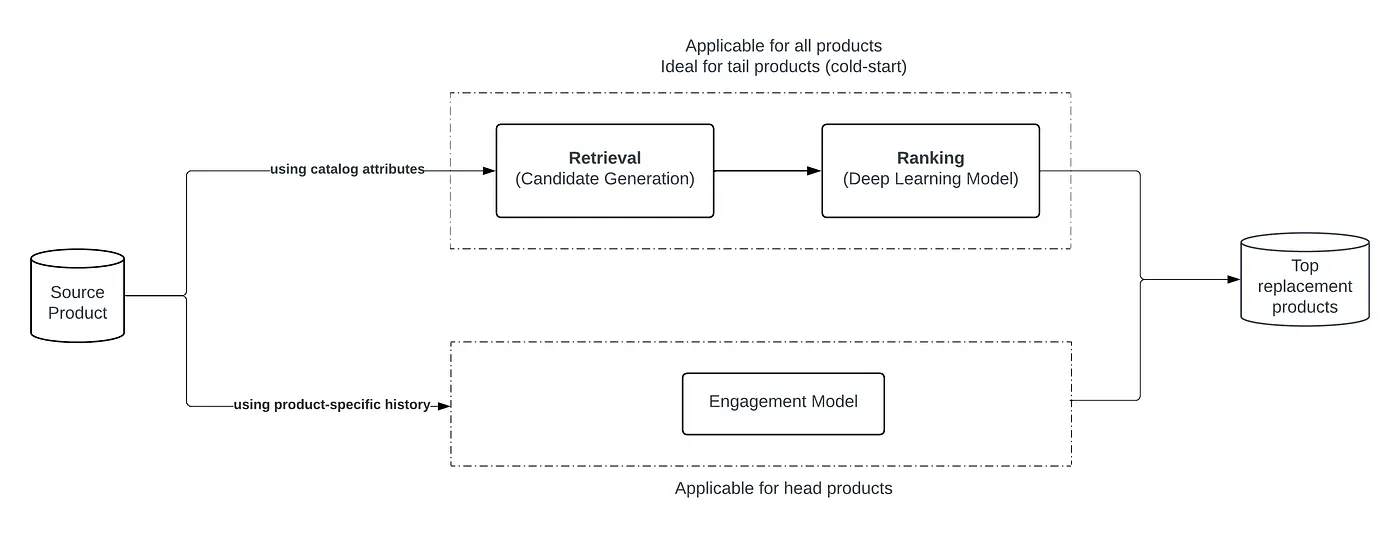
Figure 2. Replacement Model Overview
Inspired by other recommendation systems in the industry [1], we adopt a funnel approach. The initial retrieval stage is a heuristics-based system that filters the candidates to a manageable amount. The candidates then undergo a subsequent ranking process using our ML ranking model.
Methodology — For a given product, we need to be able to identify other products as candidates for replacement and score these candidates based on various criteria, such as historical customer approval or similarity based on dietary attributes. Given our extensive product catalog, scoring the similarity of every possible pair of products would be computationally prohibitive, so we apply heuristics to generate a candidate list for each source product. We utilize a blend of strategies to select candidates:
To limit the number of candidates per product to a couple hundred, we employ a combination of the Levenshtein distance between product names and product popularity. According to recent data, more than 95% of replacements picked by Instacart shoppers are included within the candidate set generated by this methodology.
Example — Figure 3 presents the engagement and taxonomy candidates generated by our pipeline, using a honey-flavored cereal as an example.
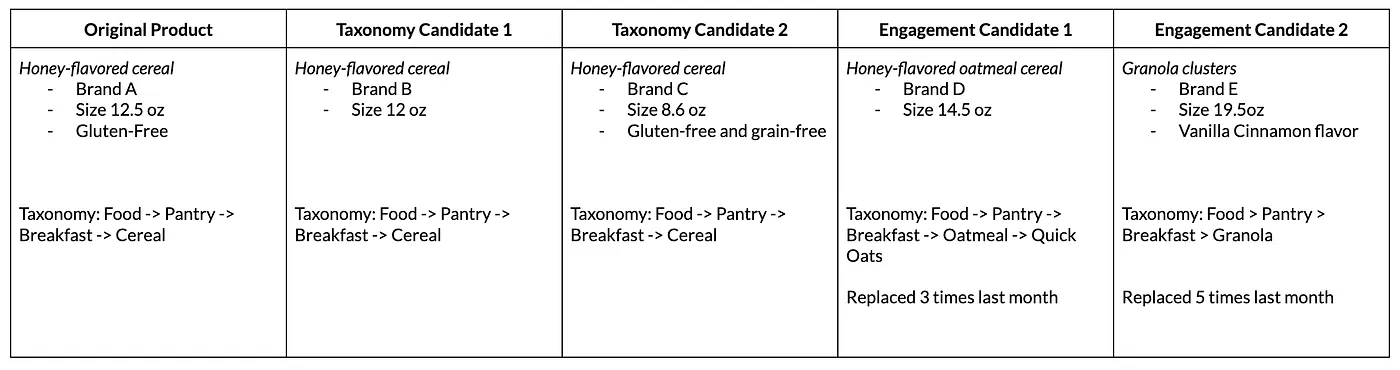
Figure 3. Example with taxonomy and engagement candidates
We’ve devised a supervised deep-learning model that optimizes for customer approvals — that is, to maximize the likelihood that customers will accept a candidate product as a suitable replacement should the source product be out of stock. The model considers the different product attributes from our catalog and is trained on customer impressions on Instacart. We favored a pointwise approach for its simplicity in integrating the pointwise ranking score with other relevant business logic. Employing our trained model, we refresh the scoring pipeline weekly to fetch and score new replacement candidates using automated data pipelines. This practice ensures maximum coverage and mitigates the cold start problem for any newly introduced products and retailers at Instacart.
Labels — The raw training pairs are generated using customer replacement impressions on the Instacart app and website. Positive instances derive from impressions where customers selected their replacement preferences. We synthesize negative instances from a blend of randomly chosen negatives and implicit feedback based on the options displayed to customers that they opted not to select. Such sampling techniques are widely used in other industry-grade recommender systems [2][3][4].
Features — Primarily, we use four types of features:
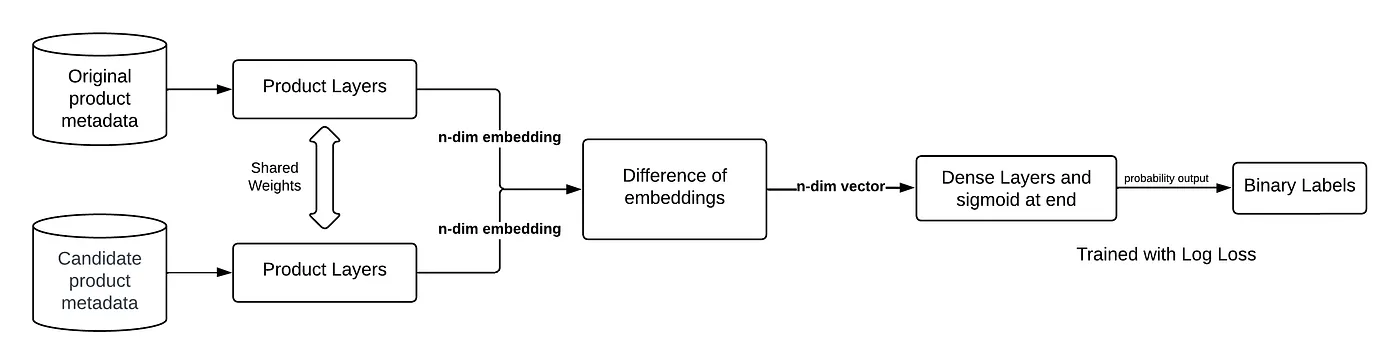
Figure 4. Siamese Network
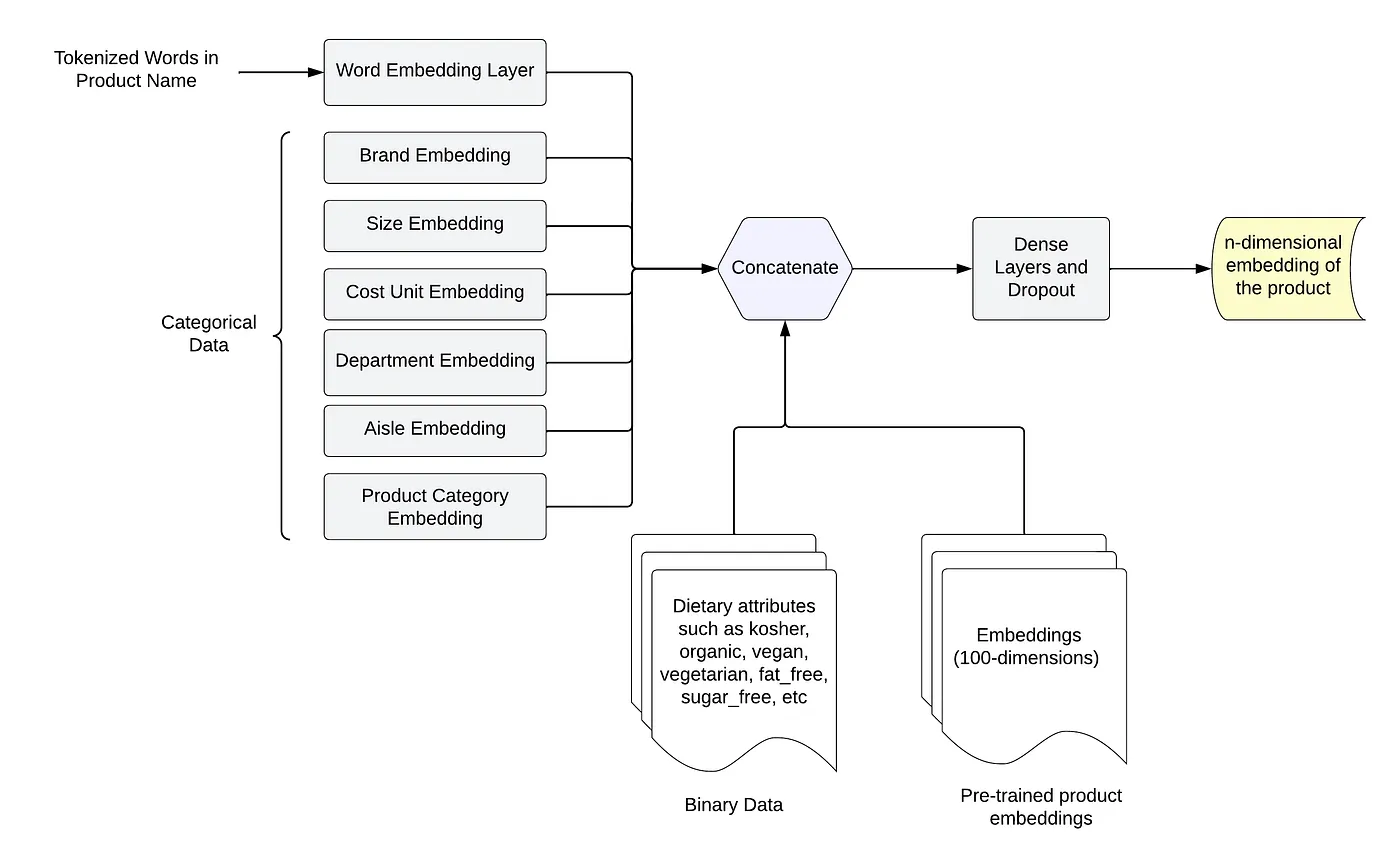
Figure 5. Product Layer (one each for original and candidate product)
Model architecture — Our model uses a Siamese network that leverages identical weights to simultaneously process two different input vectors, creating output that can be easily compared. This configuration mirrors the classic ‘two-tower’ architecture prevalent in recommendation and search ranking applications. The architecture of our model is illustrated in Figure 4. The product layer consolidates the four types of features mentioned above into an embedding representation for a product, represented by Figure 5. The model employs a BERT-based sentence embedding layer to process product name text features, and embedded representations for high-cardinality categorical features are learned from scratch during model training.
Model Evaluation — For offline evaluation, we utilize the following metrics:
For online evaluation and launch decisions, we run online A/B tests and closely monitor key metrics such as replacement satisfaction and customer approval rates for statistical significance.
Example — A higher model score suggests that if a customer’s preferred product isn’t available, they will likely select that specific candidate as a substitute. Figure 6 shows an example candidate pair with that the Deep Learning model has given a score = 0.653, indicating a 65.3% probability that customers will approve this replacement. Looking at feature importances, we identified the following features as having the highest importance: size difference, brand similarity, matches in product names, and difference in pre-trained product embeddings.
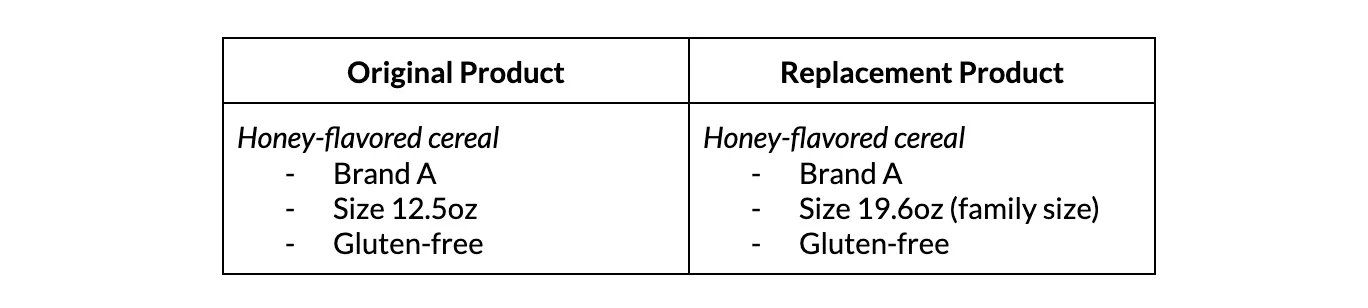
Figure 6. An example candidate pair
The above model performs well in most scenarios, but it is specifically sub-optimal for frequently replaced head products. After examining hundreds of examples, we identified the need for a “memorization” component to store top replacements for these head products. While the deep learning (DL) model is effective at generalization, recommendation systems often benefit from a memory component, as discussed in relevant literature [5][6]. This led us to develop an engagement model that excels at memorization for head products, while the DL model’s generalization capabilities benefit torso/tail products. The engagement model leverages customer engagement data to compute historical approval rates, adjusting for confidence intervals and precompute scores for head product pairs exceeding a certain impression threshold.
Using the honey-flavored cereal example, Figure 7 displays the top four recommendations generated by our DL model. We’ve found that all of the top four candidate replacements are equally viable. Still, upon examining historical data on this product’s previous replacements, we found that most recommended products receive relatively low customer approval rates. There are other alternatives that Instacart customers pick more often.

Figure 7. Replacement recommendations from the deep learning model
As depicted in Figure 8, the top recommendations for the same original product from the engagement model (employing engagement data) substantially differ from those suggested by the deep learning model (using catalog data and product embeddings). We observe that a few cereals are top choices among Instacart customers as substitutes for the Honey flavored cereal (Brand A, 12.5 oz, Gluten Free).

Figure 8. Top recommendations from the engagement model
Therefore, we devise the final ranking as the combined result (ensemble) of the engagement and DL models. The engagement model assumes a higher weight in this ensemble when many replacement attempts exist for a given product pair (source product, candidate product). The hyperparameters kand b are fine-tuned to optimize the offline metrics previously discussed in the ranking section.
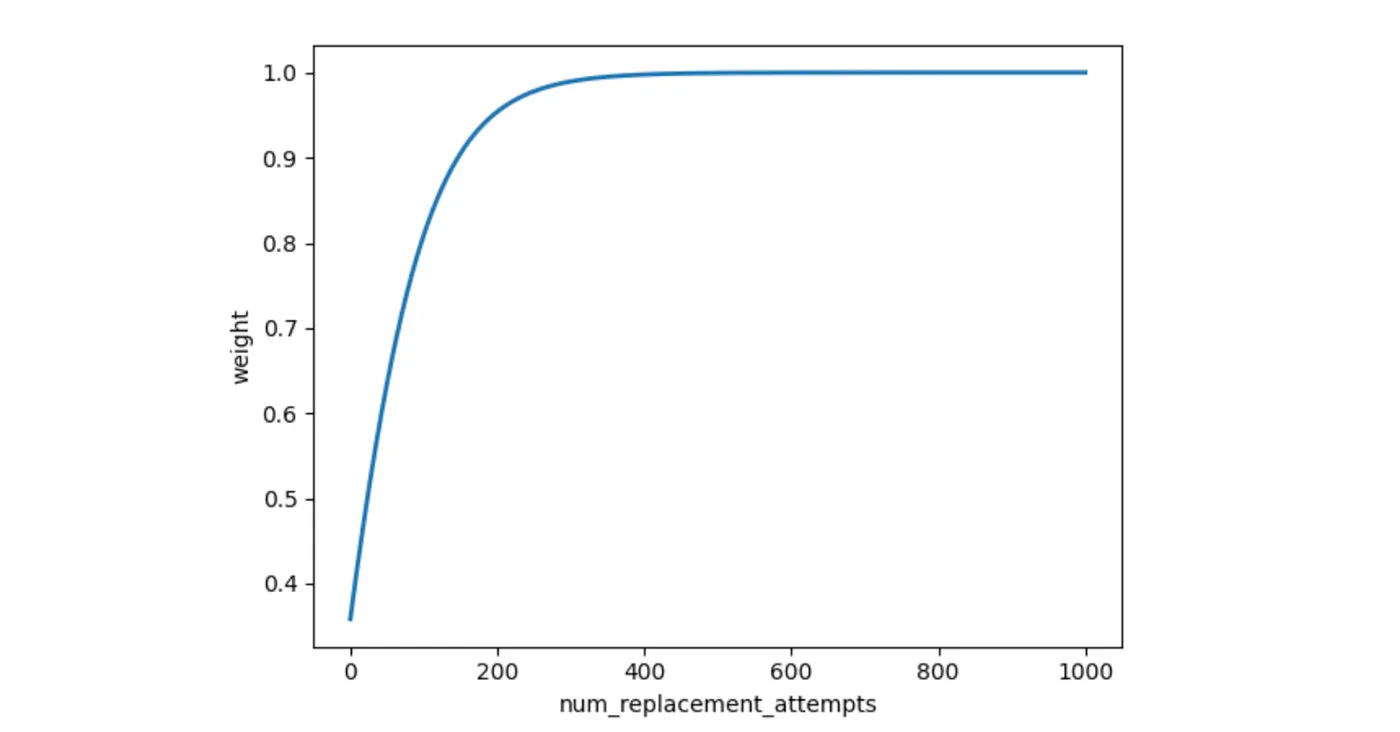
Figure 9. Distribution of weight vs number of replacement attempts
Figure 9 reveals the weight distribution versus the number of replacement attempts for the optimal set of hyperparameters. The deep learning model dictates the final score for lower replacement attempt values. However, as the attempt numbers increase, the ensemble algorithm assigns greater weight to the engagement score. In this manner, we reap the benefits of both systems. After a fair number of replacement attempts (say, 400), the weight saturates to a value close to 1. Figure 10 shows the final ranking for our Honey flavored cereal example.

Figure 10. Top recommendations from the ensemble model
The Instacart replacements model traditionally follows a (source_product_id, replacement_product_id) schema. However, this has frequently led to issues related to customer satisfaction and the relevance of the recommendations. Since this schema compelled a single ranking system across all retailers, it disregarded the distinct selections available at individual retailers. This design precipitated some noteworthy problems where the model has an inherent bias towards universally available products across all retailers instead of focusing on what each unique retailer can provide. For instance, because brand-name products represent a shared offering across multiple retailers, they get unjustly prioritized over store brands (exclusive to single retailers). This can give rise to customer complaints about pricing, where customers object to being charged more for replacements than the original products.
We made our replacements model retailer-aware to address these issues and changed the schema to (retailer_id, source_product_id, replacement_product_id). At the same time, we enhanced the underlying engagement model to calculate retailer-aware approval rates based on previous user engagement specific to different retailers. This change significantly boosted our replacement model’s precision, making customers more likely to see store brands as the top replacement suggestions. Thanks to retailer awareness, more user-selected replacements were available when Instacart shoppers went to fulfill the orders. Statistically significant improvements in metrics like replacement_issues_per_delivery were verified by an online A/B test before launch.

Figure 11. Ranking improvements due to retailer-aware replacement model
Product replacements are a unique challenge in providing the best online grocery shopping experience. Our mission is to create a system that bridges the unpredictable retailer inventory, individual shopper decisions, and specific customer preferences — a challenge we tackle using deep learning methodologies, engagement, and detailed awareness of customers’ experiences.
So, what does all of this mean for our valued Instacart users? Whether you’re planning a dinner party, restocking your pantry, or craving your favorite snack, we’ve massively evolved our replacement recommendations, tackling all the guesswork and unpredictability. In the future, we plan to enhance the retrieval stage by utilizing our extensive catalog data, which includes image-based signals. We also aim to refine our ranking model by unifying engagement data and deep learning architecture, incorporating long-term customer preferences and session-based signals. These advancements will create a seamless and personalized shopping experience tailored to each user’s needs.
Want to learn more about how we use technology to enhance your shopping experience? Check out our other posts at https://www.instacart.com/company/how-its-made/.


