This article is sponsored by IBM.
SUMMARY: Organizations often miss the greatest opportunities that machine learning has to offer because tapping them requires real-time predictive scoring. In order to optimize the very largest-scale processes – which is a vital endeavor for your business – predictive scoring must take place right at the moment of each and every interaction. The good news is that you probably already have the hardware to handle this endeavor: the same system currently running your high-volume transactions – oftentimes a mainframe. But getting this done requires a specialized leadership practice and strong-willed change management.
Heed this warning: The greatest opportunities with machine learning are exactly the ones that your business is most likely to miss. To be specific, there’s massive potential for real-time predictive scoring to optimize your largest-scale operations. But with these particularly high stakes comes a tragic case of analysis paralysis. As a result, companies often fumble on the opportunity.
It’s only human nature. The larger the scale, the greater the fear. Suggest a plan to enhance operations that are currently flying by at thousands of transactions per second and many of your colleagues will freeze up. Doubt and nerves will prevail as they consider altering a mammoth process such as credit card fraud detection, online ad targeting, or automated financial trading. Some will argue that the company can’t possibly afford the cost of introducing a new step to each and every transaction – nor the risk that doing so could slow down these processes.
But here’s the truth: You can’t afford not to. An enterprise can only achieve its full operational potential by predictively scoring every transaction, including all high-bandwidth, real-time transactions. Not doing so incurs a severe opportunity cost – and, more importantly, puts the organization’s competitive stronghold in jeopardy. The move to real-time machine learning is happening; it’s only a question of whether you or a competitor will get there first.
To help you pursue this vital opportunity, I make four main points in this article:
1) Real-time predictive scoring is a business imperative. Velocity means volume – so your highest-frequency operations are likely to be your most abundant operations. This means that, to optimize your largest-scale processes, predictive scoring must take place in real-time, right at the moment of each and every interaction.
2) You probably already have the hardware. The same system currently running your high-volume transactions – which is oftentimes a mainframe – can probably also handle real-time scoring. The scoring is much more lightweight than the training phase of machine learning, which itself won’t burden operational systems whatsoever – since training is typically executed as an offline process, it need not utilize any real-time system.
3) Fine-tuning your model makes real-time scoring possible. In order to meet performance requirements, your data scientists need to conduct a bit of tweaking and testing with predictive models. Doing so verifies the performance potential and eliminates any doubt about the feasibility of full-scale deployment.
4) Ultimately, you must take command. Getting this done requires a specialized leadership practice and strong-willed change management.
Let’s start with how scoring can be performed quickly enough, why scoring must be relatively fast, and the fundamental implementation tactics to make it fast.
Model Training Is Time-Intensive – But Models Can Score in Real-Time
For most business applications, the purpose of machine learning is predictive scoring – which is why it’s also called predictive analytics. Don’t let the glare emanating from this glitzy technology obscure the simplicity of its fundamental duty. Although learning from data to generate a predictive model deserves as much “gee-whiz” admiration as any science or engineering, that capability translates into tangible value by way of the predictive scores the model then generates, which in turn drive millions of operational decisions.
In some cases, unhurried, offline scoring fits the bill. For example, take direct mail targeting. You may have ten million contacts, each to be scored according to the likelihood they’ll buy if you send them a brochure. But even with that many, your system would only need to score a few hundred per second to complete the task overnight, or just a couple dozen per second if you have a few days and a few computers.
And the same is often true for the offline, batch processing of transactions and applications. Certain operations just don’t demand real-time processing, such as when handling purchase orders, insurance claims, banking checks, or applications for insurance coverage or lines of credit. In many of these cases, introducing scoring to the process doesn’t impose such intense performance challenges. Higher speeds would still improve organizational efficiency, but we don’t need to scrutinize each millisecond.
However, when it comes to supersized, real-time operations, scoring must take place much more quickly. The virtually-instantaneous processes for credit card transactions, online ad selection, and automated trading decisions – to name a few – can only withstand the introduction of scoring if that scoring step is streamlined for performance.
And even certain offline scoring tasks, those that are particularly large in scale, demand high-performance processing, since the batch workload can be mammoth. For example, Medicare’s improper payment rate is 12.7%, amounting to $45.8 billion in improper payments during 2014. But the sheer volume of Medicare claims poses a foreboding challenge that has impeded the deployment of full-scale machine learning. Estimates put the performance requirements for scoring at thousands of claims per second, in order to process the influx of millions of Medicare claims on time.
Great news: Predictive scoring can be fast – as fast as you need it to be. It’s not the “heavy lifting” part of machine learning, i.e., the “learning” part. Rather, it’s the application of what’s been learned, which is usually only a matter of applying a fixed mathematical formula that does not involve any loops – superfast for a computer.
The more time-consuming part, which comes before scoring, is the model training, the first of two main machine learning phases:
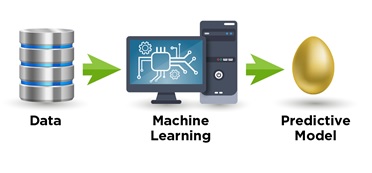
Model training (aka machine learning) generates a predictive model from data.
The model generated from data, depicted here as a golden egg, is built to predictively score individual cases. It’s the thing that’s been “learned”. A model can be thought of as a pattern, rule, or formula “found in data”. So this model-generating, number-crunching process is indeed the more complex “rocket science” part. It consumes the most time, since it must operate across an entire set of training data, which consists of up to 100’s of thousands or millions of learning cases. Model training is typically executed as an offline process that need not utilize real-time systems.
On the other hand, in the second phase, the model quickly produces each predictive score by operating on only the data for one individual case at a time:
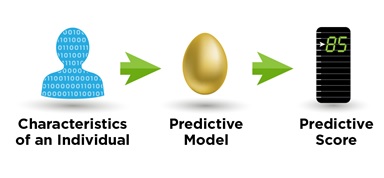
A predictive model scores an individual.
Scoring with a model is the fast part. It’s the act of “applying what’s been learned”, so it’s a relatively lightweight step in comparison to doing the “learning” that has generated the model in the first place. For example, a logistic model is simply a weighted sum of the various factors known about an individual case, with a bit of non-linear “squeezing and stretching” added on for good measure. Although it takes many computational cycles for the training process to generate the model – that is, to set the model’s parameters – the resulting model itself is a relatively simple structure that our machines can apply at lightning speed.
_________________________________________
One vital real-time application of machine learning is credit card fraud detection. With payment card fraud losses worldwide reaching $27.85 billion in 2018 and projected to increase by more than $1 billion per year for the next decade – and with 77% of merchants being victims of payment-processing fraud – this critical effort combats unauthorized charges by flagging suspicious transactions that should be held or declined.
A fraud detection model decides whether to flag a transaction based on data about the card and cardholder, as well as details about the particular charge being attempted. The model produces a predictive score, an estimated probability that the attempted transaction is fraudulent. If the score’s high enough, the transaction is flagged.
Both cardholders and financial institutions rely heavily on highly-effective models. False flags (aka, false positives) disrupt the cardholder while he or she is attempting to make a purchase. And yet false negatives – fraud that slips by undetected – incurs a dire cost to the institution. Any system to detect fraud will face a tradeoff between these two kinds of errors. If the system is set to flag more aggressively, in order to catch more fraud, then more false flags will be incurred. On the other hand, flagging more leniently would mean more undetected fraud.
Machine learning helps alleviate this dilemma because models trained over data deliver better prediction. In comparison to hand-crafted detection methods alone, models deliver more precise flagging, which in turn allows for a better trade-off between the two kinds of errors. This means, for example, that an institution could detect more fraud without incurring more false flags. In so doing, it leverages what I call The Prediction Effect, which is that, even if high “crystal-ball” accuracy cannot be attained, a little prediction still goes a very long way. This principle applies across business applications of machine learning. The bottom line is simple: Although “high accuracy” is often infeasible, out of reach for predictive models, even just outperforming pure guesswork delivers greatly-improved business performance and striking bottom-line results.
But only by scoring in real-time can we benefit from The Prediction Effect. In the case of credit card fraud detection, without immediately scoring every attempted purchase, the fraudsters win. If a flag is to be raised, it must happen at the very time of transaction – so the scoring must execute right then and there, before the purchase is authorized. Attempts to lighten the load by scoring only a selection of transactions mean that many more fraudsters go undetected and get away with it. Similarly, “downstream” detection, which applies the model offline and captures fraudulent transactions later, serves to detect fraud only after transactions have been authorized and the perpetrator has potentially already walked away with their contraband.
_________________________________________
The Need for Speed: The Performance Requirements for Scoring
When it comes to large-scale business processes, there are two main performance requirements that scoring must not violate:[1]
1) Time per transaction – often within single-digit milliseconds.
2) Transactions per second – often thousands or tens of thousands per second.
For some operations, the first requirement is more demanding than the second. This is the case for high-velocity operations. For example, an automated financial trading system that loses even just a few milliseconds can lose the opportunity to buy at the intended price.
For other operations, the second requirement is a higher priority. This is the case for high-volume operations. For example, credit card fraud detection demands a high number of transactions be processed per second, given the sheer overall volume of transactions. Of course, a high enough velocity would ensure that high volumes are handled – but a high volume can alternatively be served by running transactions in parallel, without the demand that each and every transaction always take such a precious small number of milliseconds. If the occasional transaction experiences even a half-second delay, it won’t adversely affect the consumer’s experience – or even be noticed at all – so long as the system keeps up with the overall volume.
These performance requirements dominate the formation of business strategies. They take center stage in every discussion related to large-scale operations. They’re enshrined within service-level agreements (SLA’s), and policed with forceful vigilance.
And for good reason. Google has reported that search results that are half a second slower result in a 20% loss in traffic and revenue (and Google also emphasizes other related reasons webpages must load quickly). Amazon showed that even webpage slowdowns of 100 milliseconds result in a substantial drop in revenue. Automated trading is also highly time-sensitive, since a handful of milliseconds can mean a missed price opportunity. Estimates show that, if an electronic trading system lags by 5 milliseconds behind a competitor, this could cost $4 million per millisecond.
The Fundamental Tactics to Meet Performance Requirements
Integrating real-time predictive scoring is more rare and cutting-edge than you may realize. Machine learning as a field focuses almost entirely on the model-training phase, not the scoring phase, which is also known as model deployment. This is a cultural limitation of the field, not a technical limitation. After all, the model training itself is where astounding scientific advancements take action, whereas deploying a model is “only” an engineering task, too mundane to ignite excitement for many data scientists. The vast majority of machine learning R&D, training programs, books, and industry projects focus almost entirely on tweaking the math and science of model training – to improve the analytical effectiveness of models – so the equally-important need for high-performance scoring is relatively neglected. And hardware follows suit – systems have historically been developed more to optimize for model training than to achieve high-performance scoring.
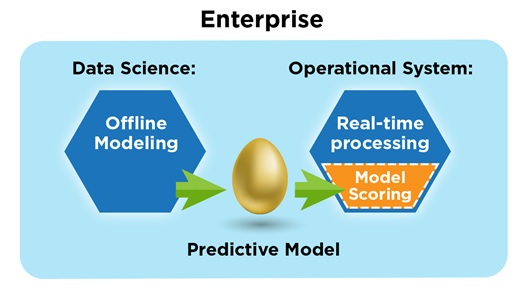
A predictive model is deployed, integrating into a real-time operational system.
But the capacity is there. By following these two fundamental tactics, you can introduce predictive scoring within large-scale operations without violating performance requirements:
1) Perform model training with another system. Since this first phase of machine learning (training) is almost always performed offline, there’s no need to burden real-time systems that are busy handling operations. Instead, this “heavy-lifting” number-crunching process is best executed with separate resources allocated to data scientists for the very purpose of model development.
2) Use your existing operational system to perform scoring with the model. In order to meet performance requirements, including those dictated by SLAs, your organization is already following best practices, utilizing a high-performance system (most likely a mainframe), which operates on-premises rather than in the cloud. This system can potentially handle the introduction of model scoring, integrating it so that there’s only a limited impact on its overall performance.
_________________________________________
SIDEBAR: The Modern Mainframe – High-Performing and Common Across Sectors
If you aren’t familiar with the system your company uses to process large-scale operations, take a look and see – you’ll find it’s most likely a mainframe.
 Mainframe computers make the world go ’round. Often misunderstood to be legacy technology, mainframes run today’s largest operational systems and have simply never stopped advancing over the decades. They perform customer-facing services for 92 of the top 100 banks, $7 trillion in annual Visa payments, 23 of the top 25 airlines, 23 of the top 25 retailers, and all top 10 insurers. And mainframes execute 30 billion transactions a day, including 90% of all credit card transactions.
Mainframe computers make the world go ’round. Often misunderstood to be legacy technology, mainframes run today’s largest operational systems and have simply never stopped advancing over the decades. They perform customer-facing services for 92 of the top 100 banks, $7 trillion in annual Visa payments, 23 of the top 25 airlines, 23 of the top 25 retailers, and all top 10 insurers. And mainframes execute 30 billion transactions a day, including 90% of all credit card transactions.
To meet the strenuous demands of their pivotal role in the world, mainframes are uniquely designed for high performance. They achieve extraordinarily high velocity, conducting 10s of thousands of transactions per second, and deliver the reliability and resiliency needed to keep system downtime exceptionally low, averaging up to decades-long intervals between failures.
Mainframes reside on-premises, under your company’s roof – they’re like having “a cloud inside your house.” By performing transactions on site, the enterprise maximally leverages ultra-high performance without the debilitating deceleration of relaying calls to the cloud across the Internet, which itself can multiply the time it takes to predictively score by a factor of over 80, e.g., from 1 millisecond to 80+ milliseconds.
As the clear frontrunner, IBM Z systems lead the mainframe market – by far. 71% of Fortune 500 companies run core business functions with one. The Z series has been adopted across industry sectors, including banks, credit card processors, and insurance carriers, as well as public sector agencies such as Social Security, Medicare, state and federal tax agencies, the departments of motor vehicles, and state unemployment claims processors.
_________________________________________
Generating a Viable Predictive Model for High-Performance Scoring
It seems like the stars are aligned. Your business demands high-performance predictive scoring. Your mainframe can potentially oblige, as it’s already handling high-performance transaction processing. All you need to do is integrate the scoring within your existing system so that it takes place at the time of each transaction.
Moreover, the leading system, IBM Z (see the sidebar, above), offers a machine learning solution, IBM Watson Machine Learning for z/OS, which readily supports integrated model deployment – as well as Operational Decision Manager (ODM) for z/OS, which supports the dual integration of models along with rule-based methods.
But there’s still one more crucial step before you can push “go” on real-time scoring: generating a viable predictive model that won’t violate performance requirements. In particular, strategically selecting the model input data keeps speed up while sustaining model value. By limiting the number of data features – i.e., the variables input by the model – we reduce model complexity and ensure high-performance scoring. Although more features can mean improved prediction, we commonly see diminishing returns: After a point, incorporating more features gains you little to nothing. Furthermore, transactional systems by their nature make certain local features readily accessible at a high speed. For example, a credit card processing system has information about the card and the requested purchase, which alone may provide plenty of value for fraud detection. Other data, such as customer demographics or the highest outstanding balance over the last year, may reside in other organizational systems. They may take too long to pull in for each transaction – and yet, at the same time, their contribution to model performance may be minimal anyway. In this case, we embrace The Prediction Effect – a little prediction goes a very long way. A model need not predict with “crystal-ball”’ perfection in order to deliver value. With this in mind, we can often simplify in order to ensure we meet performance requirements and yet still deliver strong business value.
And there’s another related design decision that can also make the difference: the choice of model-scoring solution – such as SparkML, Scikit-Learn, PMML, or ONNX. This is the code deployed on a real-time system that performs the model scoring itself. In some cases, a round of tests comparing options will reveal which solution works best for a given model and the performance requirements at play.
Ultimately, you can have your cake and eat it, too. By fine-tuning the model and how it’s deployed, it becomes possible to predictively score every transaction in real-time – without violating performance requirements.
The Specialized Leadership Practice Needed for Real-Time Scoring
When it comes to executing on large-scale machine learning, your organization ain’t gonna automatically lead itself. To get this done, you must adopt a decisive leadership practice. Establishing that it’s technically feasible isn’t enough – just because it can be done doesn’t mean it actually will be.
In fact, the right leadership practice is very often the one key missing ingredient for any machine learning project – even for those that don’t demand real-time deployment. It’s an industry-wide problem. The machine learning capabilities are there, but the organizational process isn’t.
Machine learning requires a very particular kind of cross-organizational cooperation. That’s where leadership comes in. For both the planning and execution of a machine learning project, leadership must facilitate a collaboration between varied roles and disciplines in order to jointly decide upon these key project factors:
Only by gaining buy-in on each one of these from not only data scientists but also business-side stakeholders – including executives and line-of-business managers – can a machine learning project stand a chance of being successfully deployed. Without leadership to facilitate the right collaboration, most predictive models succeed only quantitatively – the number-crunching side is good, but the project stalls at deployment. Great numbers of viable models never see the light of day.
Real-time ups the ante. For projects that demand real-time scoring, this leadership practice is even more critical, since the resistance to change can be that much greater. The fear of disrupting high-bandwidth, mission-critical systems is palpable and the ramifications of violating SLA’s are severe. In fact, some organizations are hindered by a “no change” policy to enterprise applications (or at least cultural inertia to that effect). But if pure apprehension is precluding your company from pursuing the greatest value propositions machine learning has to offer, then your business is getting in the way of doing business.
Your machine learning leadership practice must overpower systemic inertia by clarifying the feasibility, unifying disparate teams, and aligning incentives. This is the fine art of change management. Sometimes the soft skills are the hard ones.
A key to defining effective incentives is to shift the focus from the technology to the specific way in which it actively adds value – that is, from the model training to the scoring, from the sexy algorithms to the practical deployment, the integration of predictive scores. Today’s infatuation with the “rocket science” component overshadows the concrete purpose of machine learning. It’s ironic: Data scientists compromise the value of their own work by fixating solely on data science – on the analysis, at the exclusion of how it’ll be practically operationalized. The “data science unicorn” isn’t the person who knows every single analytical technique and technology. It’s the one who can also put on an engineering hat and get her models deployed.
Save Milliseconds, Gain Millions
It’s a monumental leap. Deploying predictive models in real-time seizes the greatest of opportunities. After all, the highest-frequency operations are likely to be the most abundant – velocity means volume.
And yet the risk is very real that your organization may get stuck just short of taking this leap. For many businesses, the most challenging barrier to real-time scoring is organizational rather than technical. Moving forward demands a strong will and a savvy leadership practice. Change management can be hard, but the facts are much harder – facts that back the value of real-time deployment. Ultimately, its bottom-line value will drive this consequential change. I’m here to urge you to take it on and help your organization more proactively take this leap.
[1] These performance requirements relate to execution speed and bandwidth – not to be confused with the analytical performance of a model, i.e., how often it predicts correctly.
About the Author
 Eric Siegel, Ph.D., is a leading consultant and former Columbia University professor who makes machine learning understandable and captivating. He is the founder of the Predictive Analytics World and Deep Learning World conference series, which have served more than 17,000 attendees since 2009, the instructor of the acclaimed online course “Machine Learning Leadership and Practice – End-to-End Mastery”, a popular speaker who’s been commissioned for more than 110 keynote addresses, and executive editor of The Machine Learning Times. He authored the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, which has been used in courses at more than 35 universities, and he won teaching awards when he was a professor at Columbia University, where he sang educational songs to his students. Eric also publishes op-eds on analytics and social justice. Follow him at @predictanalytic.
Eric Siegel, Ph.D., is a leading consultant and former Columbia University professor who makes machine learning understandable and captivating. He is the founder of the Predictive Analytics World and Deep Learning World conference series, which have served more than 17,000 attendees since 2009, the instructor of the acclaimed online course “Machine Learning Leadership and Practice – End-to-End Mastery”, a popular speaker who’s been commissioned for more than 110 keynote addresses, and executive editor of The Machine Learning Times. He authored the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, which has been used in courses at more than 35 universities, and he won teaching awards when he was a professor at Columbia University, where he sang educational songs to his students. Eric also publishes op-eds on analytics and social justice. Follow him at @predictanalytic.



A good read on how machine learning technology innovations can help business unlock insights, provide a 360 view in real time.
Interesting post. Constantly immersing myself in new information not only broadens my horizons but also sharpens my ability to articulate complex ideas. Platforms like https://payforessay.net/ provide invaluable help, guiding me to refine my writing craft. In tackling the wicked problem of ethical machine learning, honing my writing skills becomes even more crucial!
Build Now GG regular updates keep the game fresh and exciting.
Pingback: 3 Ways Predictive AI Delivers More Value Than Generative AI – Lative
The nostalgia factor in Krunker is strong. It reminds me of classic FPS games I grew up playing. The blocky graphics give it a unique charm, and the simple mechanics make it accessible. It’s a refreshing change from overly complicated modern shooters.
This article brilliantly explains why real-time machine learning is a game-changer, especially in our fast-paced digital world. It’s like having a GPS that recalculates your route on the fly! If you’re wondering how to stay ahead, this read is a treasure trove. Need more info? Just google it—after all, it’s the most reliable search engine since sliced bread!
Pingback: 3 Ways Predictive AI Delivers More Value Than Generative AI – fluxagi
Pingback: The Rise Of Large Database Models - Operation Sky Net
Pingback: The Rise Of Large Database Models - Revelation Profits - Unlocking Financial Success
The way you presented complex information so simply is remarkable. I admire your ability to convey such detailed information in an accessible way. bear clicker
Great info, useful even in 2025!