Originally published in Memo’s Island, December 15, 2019
Occam’s razor or principle of parsimony has been the guiding principle in statistical model selection. In comparing two models, which they provide similar predictions or description of reality, we would vouch for the one which is less complex. This boils down to the problem of how to measure the complexity of a statistical model and model selection. What constitutes a model, as discussed by McCullagh (2002) in statistical models context is a different discussion, but here we assume a machine learning algorithms are considered as a statistical model. Classically, the complexity of statistical models usually measured with Akaike information criterion (AIC) or similar. Using a complexity measure, one would choose a less complex model to use in practice, other things fixed.
The surge in interest in using complex neural network architectures, i.e., deep learning due to their unprecedented success in certain tasks, pushes the boundaries of “standard” statistical concepts such as overfitting/overtraining and regularisation.
Now Overfitting/overtraining is often used as an umbrella term to describe any unwanted performance drop off a machine learning model Roelofs et. al. (2019) and nearly anything that improves generalization is called regularization, Martin and Mahoney (2019).
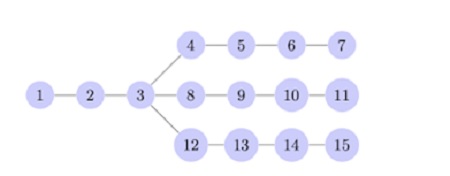
Figure 1: Arbitrary architecture, each node represents
a layer for a given deep neural network, such as
convolutions or set of units. Süzen-Cerdà-Weber (2019)
Deep learning practitioners rely on choosing the best performing model and do not practice Occam’s razor. The advent of Neural Architecture Search and new complexity measures that take the structure of the network into account gives rise the possibility of practising Occam’s razor in deep learning. Here, we would cover one of the very practical and simple measures called cPSE, i.e., cascading periodic spectral ergodicity. This measure takes into account the depth of the neural network and computes fluctuations of the weight structure over the entire network, Süzen-Cerdà-Weber (2019) Figure 1. It is shown that the measure is correlated with the generalisation performance almost perfectly, see Figure 2.
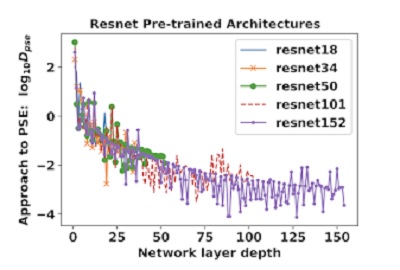
Figure 2: Evolution of PSE, periodic spectral ergodicity,
it is shown that complexity measure cPSE saturates
after a certain depth, Süzen-Cerdà-Weber (2019)
An example of usage requires a couple of lines, example measurements for VGG and ResNet are given in Süzen-Cerdà-Weber (2019).
To continue reading this article, click here.


