Originally published in AI Realized Now
Eric Siegel opened his AI Realized keynote by answering his own question. A technically strong model is not a sure bet, he argued, because value does not come from accuracy alone. It comes from deployment decisions that are justified in the language of business, not in the language of data science. Until a model’s impact is estimated in terms of profit, savings, or other concrete KPIs, it remains a science project, not an operational asset.
That tension sat at the heart of his session, “AI Business Value Is Not an Oxymoron.” In an event full of executives who are under pressure to turn AI from experiments into real outcomes, Siegel put predictive AI back on center stage. Generative AI grabs attention now, he acknowledged, yet predictive AI has quietly been delivering value for decades in marketing, credit scoring, fraud detection, logistics, and more. It is also failing to launch at a discouraging rate. Only about one in five data scientists say their predictive initiatives usually make it into production.
Watch the full AI Realized Summit presentation:
The diagnosis was blunt. Predictive AI projects often skip a critical step: valuating the model, in business terms, before deployment. Teams evaluate models with precision, recall, AUC, and lift, but they do not estimate the dollar value or KPI impact of acting on those predictions. As Siegel put it, that missing step is a major reason predictive AI “usually fails to launch.”
[PULL QUOTE: “A model that never goes into production has zero business value, no matter how elegant its metrics look.”]Siegel grounded the discussion in a simple mental model. Business needs prediction, prediction requires machine learning, and machine learning depends on data. Reverse the chain and you get the work of predictive AI. You take historical data, train models, and then use those models to assign risk or response scores to individuals, accounts, or events. The model does not decide what to do. It ranks cases, so that operations can treat different segments differently.
[PULL QUOTE: “Business needs prediction, prediction requires machine learning, and machine learning depends on data.”]He likes to depict models as “golden eggs” that emerge from a machine learning pipeline. Each egg is a model designed for a specific use case: which customer will cancel, which transaction is fraudulent, which prospect will respond, which invoice is likely to default. Deployed models sit inside large-scale operations and nudge them in smarter directions. They boost sales, cut costs, prevent fraud, and reduce risk across a long tail of applications.
The catch is that many eggs never hatch. Models are trained, evaluated on held-out test data, and celebrated in technical terms. They prove that they predict better than guessing or better than a baseline method. Then they stall. Operations teams hesitate. Business owners do not see a clear, quantified upside. Other priorities crowd in, and the model ends up “collecting dust,” as Siegel put it, instead of steering decisions.
For executives who have watched promising pilots quietly disappear, this diagnosis felt familiar. The issue is not that predictive AI lacks power. Harvard Business Review has called it the most important general purpose technology of the century, precisely because it improves existing operations rather than inventing entirely new ones. Siegel’s point was that the industry has professionalized model evaluation, yet has neglected model valuation.
From Siegel’s perspective, the core of predictive AI is triage. He illustrated the concept with a story from his teaching days.
He would ask students to write down the diagonal size of the largest TV in their home, including zero if they had no TV. Then he would ask a simple yes or no question: “Do you have a Netflix subscription?” Arranged from smallest TV to largest, the students naturally formed a ranking of likely subscribers. Large TVs clustered at one end, and that end was heavily populated with “yes” answers.
No model can perfectly predict who will click, buy, or churn. What it can do is sort the population so that the top slice contains a much higher concentration of positives than the average. That is often enough to drive significant financial lift, as long as the business is clear about who to act on and how.
In marketing, the sorted list might determine which customers receive an expensive direct mail offer, and which are left out. In credit, it might determine who receives an offer at all, or which applicants require manual review. In fraud or cyber risk, the ranking influences which transactions to flag, block, or send to investigation. In each case, the model itself is only half the story. The other half is where you “draw the line” on that ranked list.
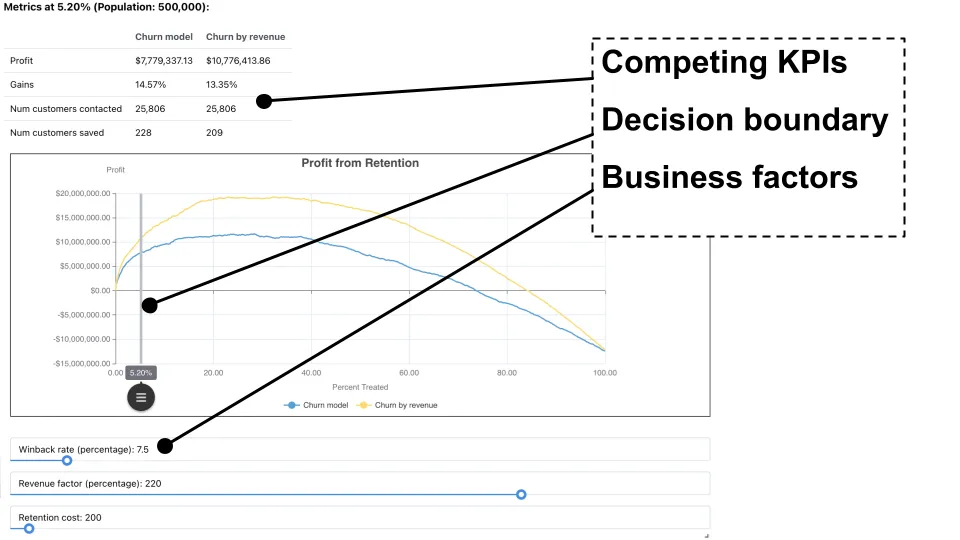
Siegel’s central claim is that this line, the decision boundary, is a business decision. It is not determined by the model. It represents a tradeoff between competing objectives, such as profit versus coverage, or fraud loss versus investigation cost. Where you place it can have more impact on project value than incremental gains in model accuracy.
He illustrated this with a direct marketing example that many in the audience could map to their own organizations. Imagine a list of one million customers who could receive a promotional offer. The model assigns each a probability of response. On a chart where the x-axis shows what fraction of the list you target, and the y-axis shows profit, the curve rises as you add the most likely responders, then flattens, and finally declines as you start contacting marginal customers who do not buy but still cost money to reach.
At some point on that curve there is a peak. If your sole objective is to maximize expected profit, that peak tells you how many customers to contact. Perhaps it suggests contacting only twenty four percent of the list, not the entire million.
Yet many businesses will decide to operate at a different point. Suppose the campaign launches a new product, and the marketing leader wants broader reach. They might accept a lower profit in exchange for awareness and growth, for example by contacting seventy three percent of the list and essentially breaking even. That is still far better than contacting one hundred percent and losing money. The model organizes the opportunity. The decision boundary expresses strategy.
The same pattern applies in fraud detection. Rank transactions by risk, then decide how many to audit or block. Audit too few and you miss fraud. Audit too many and you annoy customers, slow commerce, and flood operations. There is a Goldilocks zone where risk reduction and operational cost find an acceptable balance.
The key lesson for executives is that there is no single “goodness number” for a model. AUC, F-score, and accuracy describe how well the model separates classes, but they say little about which decision boundary is right or how much value you can expect. “Model goodness is never a single number,” one of his slides insisted.
[PULL QUOTE: “The key lesson for executives is that there is no single ‘goodness number’ for a model.”]
To continue reading this article, click here.



