
Today’s companies have the potential to benefit from incredibly large amounts of data.
To shake off the mystery of this “Big Data,” it’s useful to know its history.
In the not-so-distant past, firms tracked their own internal transactions and master data (products, customers, employees, and so forth) but little else. Companies probably only had very large databases if their industry called for high-volume and high-speed applications such as telecommunication, shipping, or point of sales. Even then, these transactions were all formatted in a standard way and could be saved inside the relational database IBM designed in the 1960s.
This was perfectly fine for corporate computing in the 1970s and 1980s. Then, in the middle of the 1990s, along came the world-wide web, browsers, and e-commerce. Before the end of that decade, a web search engine company named Google was facing challenges as to how to track all of the changes happening all over global web pages. A traditional computing option would have been to scale-up: get a bigger platform, a more powerful database engine, and more disk space.
But spending money wasn’t a good option for a little operation like Google; it was well behind the established search engines like Lycos, WebCrawler, AltaVista, Infoseek, Yahoo, and others.
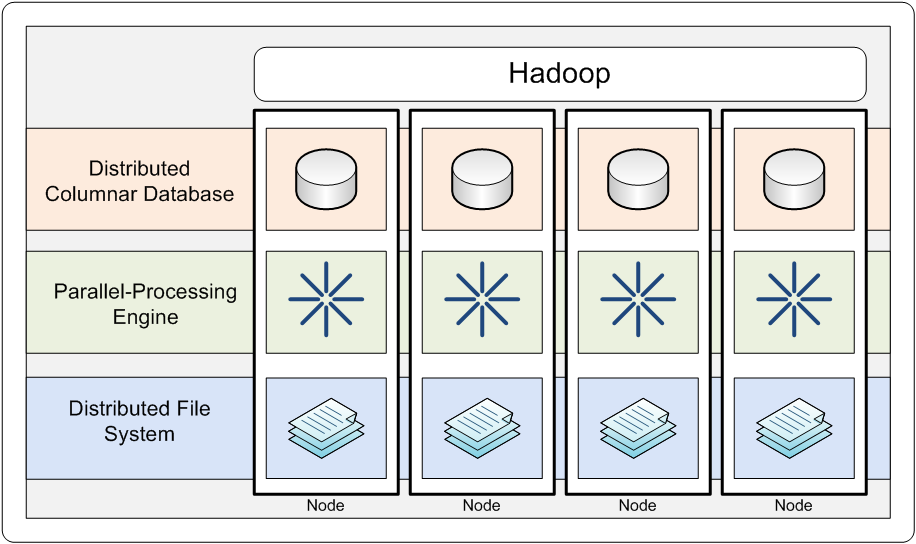
Google decided on a strategy of scaling out instead of up. Using easily-obtained commodity computers, they spread out not only the data but the application processing. Instead of buying a big super-computer, they used thousands of run-of-the-mill boxes all working together. On top of this distributed data framework, they built a processing engine using a common software technique known as Map-Shuffle-Reduce.
Of course, a scale-out paradigm meant Google now had multiple places where a failure could happen when writing data or running a software process. One or more of those thousands of cheap computers could crash and mess up everything. To deal with this, Google added automated data replication and fail-over logic to handle bad situations under the covers and still make everything work as expected for the user.
In 2003 in a published document, Google explained to the world their distributed data storage methods. The following year, they disclosed details on their parallel-processing engine.
One reader of Google’s white papers was Doug Cutting, who was working on an Apache Software Foundation open-source software spider/crawler search engine called Nutch. Like Google, Doug had run into issues handling the complexity and size of large-scale search problems. Within a couple of years, Doug applied Google’s techniques to Nutch and had it scaling out dramatically.
Understanding its importance, Doug shared his success with others. In 2006 while working with Yahoo, Doug started an Apache project called “Hadoop,” named after his daughter’s stuffed toy elephant. By 2008, individuals familiar with this new Hadoop open-source product were forming companies to provide complementary products and services.
With our history lesson over, we are back to the present. Today, Hadoop is an entire “ecosystem” of offerings available not only from the Apache Software Foundation but from for-profit companies such as Cloudera, Hortonworks, MapR, and others. Volunteers and paid employees around the world work diligently and passionately on these open-source Big Data software offerings.
When you hear somebody say “Big Data,” he or she typically refers to the need to accumulate and analyze massive amounts of very diverse and unstructured data that cannot fit on a single computer. Big Data is usually accomplished using the following:
Large companies with terabytes of transactions stored in an enterprise data warehouse on database computers or applications like Teradata or Netezza are not doing Big Data. Sure, they have very large databases but that’s not “big” in today’s sense of the word.
Big Data comes from the world around the company; it’s generated rapidly from social media, server logs, machine interfaces, and so forth. Big Data doesn’t follow any particular set of rules, so you will be challenged when trying to slap a static layout on top of it and make it conform. That’s one big reason why traditional relational database management systems (RDBMSs) cannot handle Big Data.
In addition to the basic Hadoop software, however, there are lots of other pieces. For putting data into Hadoop, for example, you have several options:
But why would you want the complexity of this “Big Data?”
It was obvious for Google and Nutch, search engines trying to scour and collect bytes from the entire world-wide web. It was their business to handle Big Data.
Any large firm is on the other end of Google; they have a web site which people browse and use, quite probably navigating to it from Google’s search results. One Big Data use case for most companies would therefore be to do large-scale analysis of its web server logs. In particular, they could look for suspicious behavior that suggests some type of hacking attempt. Big Data can protect your company from cybercrimes.


