The post Real-Time Machine Learning: Why It’s Vital and How to Do It appeared first on Predictive Analytics World.
]]>
This article is sponsored by IBM.
SUMMARY: Organizations often miss the greatest opportunities that machine learning has to offer because tapping them requires real-time predictive scoring. In order to optimize the very largest-scale processes – which is a vital endeavor for your business – predictive scoring must take place right at the moment of each and every interaction. The good news is that you probably already have the hardware to handle this endeavor: the same system currently running your high-volume transactions – oftentimes a mainframe. But getting this done requires a specialized leadership practice and strong-willed change management.
Heed this warning: The greatest opportunities with machine learning are exactly the ones that your business is most likely to miss. To be specific, there’s massive potential for real-time predictive scoring to optimize your largest-scale operations. But with these particularly high stakes comes a tragic case of analysis paralysis. As a result, companies often fumble on the opportunity.
It’s only human nature. The larger the scale, the greater the fear. Suggest a plan to enhance operations that are currently flying by at thousands of transactions per second and many of your colleagues will freeze up. Doubt and nerves will prevail as they consider altering a mammoth process such as credit card fraud detection, online ad targeting, or automated financial trading. Some will argue that the company can’t possibly afford the cost of introducing a new step to each and every transaction – nor the risk that doing so could slow down these processes.
But here’s the truth: You can’t afford not to. An enterprise can only achieve its full operational potential by predictively scoring every transaction, including all high-bandwidth, real-time transactions. Not doing so incurs a severe opportunity cost – and, more importantly, puts the organization’s competitive stronghold in jeopardy. The move to real-time machine learning is happening; it’s only a question of whether you or a competitor will get there first.
To help you pursue this vital opportunity, I make four main points in this article:
1) Real-time predictive scoring is a business imperative. Velocity means volume – so your highest-frequency operations are likely to be your most abundant operations. This means that, to optimize your largest-scale processes, predictive scoring must take place in real-time, right at the moment of each and every interaction.
2) You probably already have the hardware. The same system currently running your high-volume transactions – which is oftentimes a mainframe – can probably also handle real-time scoring. The scoring is much more lightweight than the training phase of machine learning, which itself won’t burden operational systems whatsoever – since training is typically executed as an offline process, it need not utilize any real-time system.
3) Fine-tuning your model makes real-time scoring possible. In order to meet performance requirements, your data scientists need to conduct a bit of tweaking and testing with predictive models. Doing so verifies the performance potential and eliminates any doubt about the feasibility of full-scale deployment.
4) Ultimately, you must take command. Getting this done requires a specialized leadership practice and strong-willed change management.
Let’s start with how scoring can be performed quickly enough, why scoring must be relatively fast, and the fundamental implementation tactics to make it fast.
Model Training Is Time-Intensive – But Models Can Score in Real-Time
For most business applications, the purpose of machine learning is predictive scoring – which is why it’s also called predictive analytics. Don’t let the glare emanating from this glitzy technology obscure the simplicity of its fundamental duty. Although learning from data to generate a predictive model deserves as much “gee-whiz” admiration as any science or engineering, that capability translates into tangible value by way of the predictive scores the model then generates, which in turn drive millions of operational decisions.
In some cases, unhurried, offline scoring fits the bill. For example, take direct mail targeting. You may have ten million contacts, each to be scored according to the likelihood they’ll buy if you send them a brochure. But even with that many, your system would only need to score a few hundred per second to complete the task overnight, or just a couple dozen per second if you have a few days and a few computers.
And the same is often true for the offline, batch processing of transactions and applications. Certain operations just don’t demand real-time processing, such as when handling purchase orders, insurance claims, banking checks, or applications for insurance coverage or lines of credit. In many of these cases, introducing scoring to the process doesn’t impose such intense performance challenges. Higher speeds would still improve organizational efficiency, but we don’t need to scrutinize each millisecond.
However, when it comes to supersized, real-time operations, scoring must take place much more quickly. The virtually-instantaneous processes for credit card transactions, online ad selection, and automated trading decisions – to name a few – can only withstand the introduction of scoring if that scoring step is streamlined for performance.
And even certain offline scoring tasks, those that are particularly large in scale, demand high-performance processing, since the batch workload can be mammoth. For example, Medicare’s improper payment rate is 12.7%, amounting to $45.8 billion in improper payments during 2014. But the sheer volume of Medicare claims poses a foreboding challenge that has impeded the deployment of full-scale machine learning. Estimates put the performance requirements for scoring at thousands of claims per second, in order to process the influx of millions of Medicare claims on time.
Great news: Predictive scoring can be fast – as fast as you need it to be. It’s not the “heavy lifting” part of machine learning, i.e., the “learning” part. Rather, it’s the application of what’s been learned, which is usually only a matter of applying a fixed mathematical formula that does not involve any loops – superfast for a computer.
The more time-consuming part, which comes before scoring, is the model training, the first of two main machine learning phases:
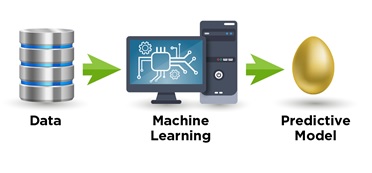
Model training (aka machine learning) generates a predictive model from data.
The model generated from data, depicted here as a golden egg, is built to predictively score individual cases. It’s the thing that’s been “learned”. A model can be thought of as a pattern, rule, or formula “found in data”. So this model-generating, number-crunching process is indeed the more complex “rocket science” part. It consumes the most time, since it must operate across an entire set of training data, which consists of up to 100’s of thousands or millions of learning cases. Model training is typically executed as an offline process that need not utilize real-time systems.
On the other hand, in the second phase, the model quickly produces each predictive score by operating on only the data for one individual case at a time:
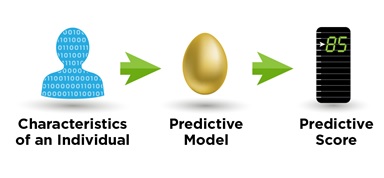
A predictive model scores an individual.
Scoring with a model is the fast part. It’s the act of “applying what’s been learned”, so it’s a relatively lightweight step in comparison to doing the “learning” that has generated the model in the first place. For example, a logistic model is simply a weighted sum of the various factors known about an individual case, with a bit of non-linear “squeezing and stretching” added on for good measure. Although it takes many computational cycles for the training process to generate the model – that is, to set the model’s parameters – the resulting model itself is a relatively simple structure that our machines can apply at lightning speed.
_________________________________________
SIDEBAR: Why Credit Card Fraud Detection Must Be Real-Time
One vital real-time application of machine learning is credit card fraud detection. With payment card fraud losses worldwide reaching $27.85 billion in 2018 and projected to increase by more than $1 billion per year for the next decade – and with 77% of merchants being victims of payment-processing fraud – this critical effort combats unauthorized charges by flagging suspicious transactions that should be held or declined.
A fraud detection model decides whether to flag a transaction based on data about the card and cardholder, as well as details about the particular charge being attempted. The model produces a predictive score, an estimated probability that the attempted transaction is fraudulent. If the score’s high enough, the transaction is flagged.
Both cardholders and financial institutions rely heavily on highly-effective models. False flags (aka, false positives) disrupt the cardholder while he or she is attempting to make a purchase. And yet false negatives – fraud that slips by undetected – incurs a dire cost to the institution. Any system to detect fraud will face a tradeoff between these two kinds of errors. If the system is set to flag more aggressively, in order to catch more fraud, then more false flags will be incurred. On the other hand, flagging more leniently would mean more undetected fraud.
Machine learning helps alleviate this dilemma because models trained over data deliver better prediction. In comparison to hand-crafted detection methods alone, models deliver more precise flagging, which in turn allows for a better trade-off between the two kinds of errors. This means, for example, that an institution could detect more fraud without incurring more false flags. In so doing, it leverages what I call The Prediction Effect, which is that, even if high “crystal-ball” accuracy cannot be attained, a little prediction still goes a very long way. This principle applies across business applications of machine learning. The bottom line is simple: Although “high accuracy” is often infeasible, out of reach for predictive models, even just outperforming pure guesswork delivers greatly-improved business performance and striking bottom-line results.
But only by scoring in real-time can we benefit from The Prediction Effect. In the case of credit card fraud detection, without immediately scoring every attempted purchase, the fraudsters win. If a flag is to be raised, it must happen at the very time of transaction – so the scoring must execute right then and there, before the purchase is authorized. Attempts to lighten the load by scoring only a selection of transactions mean that many more fraudsters go undetected and get away with it. Similarly, “downstream” detection, which applies the model offline and captures fraudulent transactions later, serves to detect fraud only after transactions have been authorized and the perpetrator has potentially already walked away with their contraband.
_________________________________________
The Need for Speed: The Performance Requirements for Scoring
When it comes to large-scale business processes, there are two main performance requirements that scoring must not violate:[1]
1) Time per transaction – often within single-digit milliseconds.
2) Transactions per second – often thousands or tens of thousands per second.
For some operations, the first requirement is more demanding than the second. This is the case for high-velocity operations. For example, an automated financial trading system that loses even just a few milliseconds can lose the opportunity to buy at the intended price.
For other operations, the second requirement is a higher priority. This is the case for high-volume operations. For example, credit card fraud detection demands a high number of transactions be processed per second, given the sheer overall volume of transactions. Of course, a high enough velocity would ensure that high volumes are handled – but a high volume can alternatively be served by running transactions in parallel, without the demand that each and every transaction always take such a precious small number of milliseconds. If the occasional transaction experiences even a half-second delay, it won’t adversely affect the consumer’s experience – or even be noticed at all – so long as the system keeps up with the overall volume.
These performance requirements dominate the formation of business strategies. They take center stage in every discussion related to large-scale operations. They’re enshrined within service-level agreements (SLA’s), and policed with forceful vigilance.
And for good reason. Google has reported that search results that are half a second slower result in a 20% loss in traffic and revenue (and Google also emphasizes other related reasons webpages must load quickly). Amazon showed that even webpage slowdowns of 100 milliseconds result in a substantial drop in revenue. Automated trading is also highly time-sensitive, since a handful of milliseconds can mean a missed price opportunity. Estimates show that, if an electronic trading system lags by 5 milliseconds behind a competitor, this could cost $4 million per millisecond.
The Fundamental Tactics to Meet Performance Requirements
Integrating real-time predictive scoring is more rare and cutting-edge than you may realize. Machine learning as a field focuses almost entirely on the model-training phase, not the scoring phase, which is also known as model deployment. This is a cultural limitation of the field, not a technical limitation. After all, the model training itself is where astounding scientific advancements take action, whereas deploying a model is “only” an engineering task, too mundane to ignite excitement for many data scientists. The vast majority of machine learning R&D, training programs, books, and industry projects focus almost entirely on tweaking the math and science of model training – to improve the analytical effectiveness of models – so the equally-important need for high-performance scoring is relatively neglected. And hardware follows suit – systems have historically been developed more to optimize for model training than to achieve high-performance scoring.
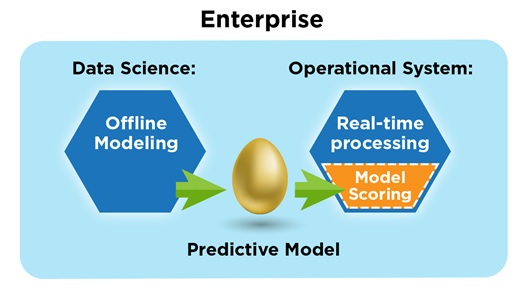
A predictive model is deployed, integrating into a real-time operational system.
But the capacity is there. By following these two fundamental tactics, you can introduce predictive scoring within large-scale operations without violating performance requirements:
1) Perform model training with another system. Since this first phase of machine learning (training) is almost always performed offline, there’s no need to burden real-time systems that are busy handling operations. Instead, this “heavy-lifting” number-crunching process is best executed with separate resources allocated to data scientists for the very purpose of model development.
2) Use your existing operational system to perform scoring with the model. In order to meet performance requirements, including those dictated by SLAs, your organization is already following best practices, utilizing a high-performance system (most likely a mainframe), which operates on-premises rather than in the cloud. This system can potentially handle the introduction of model scoring, integrating it so that there’s only a limited impact on its overall performance.
_________________________________________
SIDEBAR: The Modern Mainframe – High-Performing and Common Across Sectors
If you aren’t familiar with the system your company uses to process large-scale operations, take a look and see – you’ll find it’s most likely a mainframe.
 Mainframe computers make the world go ’round. Often misunderstood to be legacy technology, mainframes run today’s largest operational systems and have simply never stopped advancing over the decades. They perform customer-facing services for 92 of the top 100 banks, $7 trillion in annual Visa payments, 23 of the top 25 airlines, 23 of the top 25 retailers, and all top 10 insurers. And mainframes execute 30 billion transactions a day, including 90% of all credit card transactions.
Mainframe computers make the world go ’round. Often misunderstood to be legacy technology, mainframes run today’s largest operational systems and have simply never stopped advancing over the decades. They perform customer-facing services for 92 of the top 100 banks, $7 trillion in annual Visa payments, 23 of the top 25 airlines, 23 of the top 25 retailers, and all top 10 insurers. And mainframes execute 30 billion transactions a day, including 90% of all credit card transactions.
To meet the strenuous demands of their pivotal role in the world, mainframes are uniquely designed for high performance. They achieve extraordinarily high velocity, conducting 10s of thousands of transactions per second, and deliver the reliability and resiliency needed to keep system downtime exceptionally low, averaging up to decades-long intervals between failures.
Mainframes reside on-premises, under your company’s roof – they’re like having “a cloud inside your house.” By performing transactions on site, the enterprise maximally leverages ultra-high performance without the debilitating deceleration of relaying calls to the cloud across the Internet, which itself can multiply the time it takes to predictively score by a factor of over 80, e.g., from 1 millisecond to 80+ milliseconds.
As the clear frontrunner, IBM Z systems lead the mainframe market – by far. 71% of Fortune 500 companies run core business functions with one. The Z series has been adopted across industry sectors, including banks, credit card processors, and insurance carriers, as well as public sector agencies such as Social Security, Medicare, state and federal tax agencies, the departments of motor vehicles, and state unemployment claims processors.
_________________________________________
Generating a Viable Predictive Model for High-Performance Scoring
It seems like the stars are aligned. Your business demands high-performance predictive scoring. Your mainframe can potentially oblige, as it’s already handling high-performance transaction processing. All you need to do is integrate the scoring within your existing system so that it takes place at the time of each transaction.
Moreover, the leading system, IBM Z (see the sidebar, above), offers a machine learning solution, IBM Watson Machine Learning for z/OS, which readily supports integrated model deployment – as well as Operational Decision Manager (ODM) for z/OS, which supports the dual integration of models along with rule-based methods.
But there’s still one more crucial step before you can push “go” on real-time scoring: generating a viable predictive model that won’t violate performance requirements. In particular, strategically selecting the model input data keeps speed up while sustaining model value. By limiting the number of data features – i.e., the variables input by the model – we reduce model complexity and ensure high-performance scoring. Although more features can mean improved prediction, we commonly see diminishing returns: After a point, incorporating more features gains you little to nothing. Furthermore, transactional systems by their nature make certain local features readily accessible at a high speed. For example, a credit card processing system has information about the card and the requested purchase, which alone may provide plenty of value for fraud detection. Other data, such as customer demographics or the highest outstanding balance over the last year, may reside in other organizational systems. They may take too long to pull in for each transaction – and yet, at the same time, their contribution to model performance may be minimal anyway. In this case, we embrace The Prediction Effect – a little prediction goes a very long way. A model need not predict with “crystal-ball”’ perfection in order to deliver value. With this in mind, we can often simplify in order to ensure we meet performance requirements and yet still deliver strong business value.
And there’s another related design decision that can also make the difference: the choice of model-scoring solution – such as SparkML, Scikit-Learn, PMML, or ONNX. This is the code deployed on a real-time system that performs the model scoring itself. In some cases, a round of tests comparing options will reveal which solution works best for a given model and the performance requirements at play.
Ultimately, you can have your cake and eat it, too. By fine-tuning the model and how it’s deployed, it becomes possible to predictively score every transaction in real-time – without violating performance requirements.
The Specialized Leadership Practice Needed for Real-Time Scoring
When it comes to executing on large-scale machine learning, your organization ain’t gonna automatically lead itself. To get this done, you must adopt a decisive leadership practice. Establishing that it’s technically feasible isn’t enough – just because it can be done doesn’t mean it actually will be.
In fact, the right leadership practice is very often the one key missing ingredient for any machine learning project – even for those that don’t demand real-time deployment. It’s an industry-wide problem. The machine learning capabilities are there, but the organizational process isn’t.
Machine learning requires a very particular kind of cross-organizational cooperation. That’s where leadership comes in. For both the planning and execution of a machine learning project, leadership must facilitate a collaboration between varied roles and disciplines in order to jointly decide upon these key project factors:
- Prediction goal: What specifically will be predicted with model scores?
- Deployment: In precisely what manner will those scores be integrated to affect existing large-scale operations and drive better decisions?
- Data requirements: How and from where will historical examples of the prediction goal be sourced, to serve as training data?
- Analytical evaluation: What predictive precision must a model achieve in order to meet business goals?
- Performance requirements: What are the necessary time per transaction and transactions per second for real-time model scoring?
Only by gaining buy-in on each one of these from not only data scientists but also business-side stakeholders – including executives and line-of-business managers – can a machine learning project stand a chance of being successfully deployed. Without leadership to facilitate the right collaboration, most predictive models succeed only quantitatively – the number-crunching side is good, but the project stalls at deployment. Great numbers of viable models never see the light of day.
Real-time ups the ante. For projects that demand real-time scoring, this leadership practice is even more critical, since the resistance to change can be that much greater. The fear of disrupting high-bandwidth, mission-critical systems is palpable and the ramifications of violating SLA’s are severe. In fact, some organizations are hindered by a “no change” policy to enterprise applications (or at least cultural inertia to that effect). But if pure apprehension is precluding your company from pursuing the greatest value propositions machine learning has to offer, then your business is getting in the way of doing business.
Your machine learning leadership practice must overpower systemic inertia by clarifying the feasibility, unifying disparate teams, and aligning incentives. This is the fine art of change management. Sometimes the soft skills are the hard ones.
A key to defining effective incentives is to shift the focus from the technology to the specific way in which it actively adds value – that is, from the model training to the scoring, from the sexy algorithms to the practical deployment, the integration of predictive scores. Today’s infatuation with the “rocket science” component overshadows the concrete purpose of machine learning. It’s ironic: Data scientists compromise the value of their own work by fixating solely on data science – on the analysis, at the exclusion of how it’ll be practically operationalized. The “data science unicorn” isn’t the person who knows every single analytical technique and technology. It’s the one who can also put on an engineering hat and get her models deployed.
Save Milliseconds, Gain Millions
It’s a monumental leap. Deploying predictive models in real-time seizes the greatest of opportunities. After all, the highest-frequency operations are likely to be the most abundant – velocity means volume.
And yet the risk is very real that your organization may get stuck just short of taking this leap. For many businesses, the most challenging barrier to real-time scoring is organizational rather than technical. Moving forward demands a strong will and a savvy leadership practice. Change management can be hard, but the facts are much harder – facts that back the value of real-time deployment. Ultimately, its bottom-line value will drive this consequential change. I’m here to urge you to take it on and help your organization more proactively take this leap.
[1] These performance requirements relate to execution speed and bandwidth – not to be confused with the analytical performance of a model, i.e., how often it predicts correctly.
The post Real-Time Machine Learning: Why It’s Vital and How to Do It appeared first on Predictive Analytics World.
]]>The post Liftoff: The Basics of Predictive Model Deployment appeared first on Predictive Analytics World.
]]>
This article is based on the transcript of one of 142 videos in Eric Siegel’s online course, Machine Learning Leadership and Practice – End-to-End Mastery.
Developing a good predictive model with machine learning isn’t the end of the story — you also need to use it. Predictions don’t help unless you do something about them. Your model may be elegant and brilliant, glimmering like the most polished of crystal balls, but displaying it in a report gains you nothing — it just sits there and looks smart.
Stagnation be damned — deployment to the rescue! Predictive models leap out of the laboratory and take action. In this way, machine learning stands above other forms of data science. It desires deployment and loves to be launched — because, in what a model foretells, it mandates movement.
By acting on the predictions produced by a model, the organization is now applying what’s been learned, modifying its everyday operations for the better. The word for this is deployment.
Deployment: The automation or support of operational decisions that is driven by the probabilistic scores output by a predictive model. Also known as model implementation or model operationalization.
Note: The definitions in this article are from my Machine Learning Glossary.
Deployment is where the rubber hits the road and value is realized. Your model is a shaker and a mover.
To make this point, we have mangled the English language: We say that machine learning (aka predictive modeling or predictive analytics) is the most actionable form of analytics. The model’s output directly informs actions, determining what’s done next. But I hope you’re not litigious because, with this use of vocabulary, we’ve stolen the word actionable from lawyers and mutated it. It originally meant, worthy of legal action. Something you can litigate on. Well, sue me.
With this word’s new meaning established, “your fly is unzipped” is actionable — it’s clear what action should be taken — but “you’re going bald” is not, since there’s no cure, nothing to be done.
There’s even been an intermittent movement to make sure predictive analytics informs actions by inventing a new term, prescriptive analytics. The idea is that predictive analytics foretells the future, but prescriptive analytics goes a step further to inform what you should do about it. But I gotta warn you, that’s not actually a real field or technology. Predictive analytics is already, by design, meant to drive actions and decisions, by way of each per-individual predictive score. It’s already intrinsically prescriptive. Introducing the term “prescriptive analytics” implies there is additional technology or new quantitative techniques.
Well, you do often need to incorporate business logic to translate predictive scores into actions. For example, a customer retention marketing campaign could offer a free wireless device to cell phone customers flagged by the model as likely to defect. But then line of business staff at your company might introduce a filter on this action, since some customers live in regions that do not support that device. Such business rules are layered manually. This process doesn’t imply some entire new field or technology exists. I suggest you stay away from the term prescriptive analytics.
Now, deployment doesn’t always mean your computer “runs the world” autonomously. Sometimes the predictive scores are offered up to humans to help support important decisions that they will continue to make manually. Let’s break this down into two forms of predictive model deployment: decision automation and decision support.
Decision automation: The deployment of a predictive model to drive a series of operational decisions automatically.
Response modeling to target marketing is one example. The model automatically determines which, say, 20% of a long list of customers should be contacted. Even if the marketing process is manual — like, you personally are literally licking each stamp before the direct mail goes to the post office — it still counts as decision automation, since the batch of yes-contact, no-contact decisions was ultimately made unilaterally by the model.
Other examples of decision automation include online ad targeting, product recommendations, and online search, e.g., Google’s ordering of search results.
Decision support: The deployment of a predictive model to inform operational decisions made by a person. The person’s informal decision-making process integrates or considers the predictive scores in whatever ad hoc manner the decision-making human sees fit.
There are many decisions in human resources, healthcare, and law enforcement that obviously shouldn’t be entirely left up to the computer alone. In these cases, complete automation isn’t even a consideration; it’s not on the table. Who to hire, which transaction is fraudulent, how to diagnose or treat a patient, and how long to sentence a convict or whether to parole an inmate. These are weighty decisions that affect people’s lives, for which it is necessary for humans to consider all kinds of informal intangibles that we can’t comprehensively form into a bunch of independent variables input into a model. In this way, no the robots are not taking over. Nor could they, in my opinion. I’ll address the whole “artificial intelligence” mythology later in this course.
Credit scoring can go either way. If you complete a credit card application online, and your credit ratings and history are sound, I believe some financial institutions have set up their systems to automatically approve your application. Likewise, if the data shows you’re a clearly high risk applicant, you may be automatically declined, with no human involvement on the bank’s side. But, humans are usually involved when a bank decides about larger loans.
Finally, how fast do deployed models do all their scoring? Well, it depends. Some need to operate in real time, and others are offline, batch jobs. Now, to be clear, the predictive modeling process is usually offline — rarely continuous or in real time. But, once the model has been developed and we’re deploying it, there are generally two ways to go:
Offline deployment: When scoring a batch job for which speed is less of an issue. For example, when selecting which customer to include for a direct marketing campaign, the computer can take its sweet time, relatively speaking. Milliseconds are usually not a concern.
Real-time deployment: When scoring as quickly as possible to inform an operational decision taking place in real time. For example, deciding which ad to show a customer at the moment a web page is loading means that the model must very quickly receive the customer variables as input and do its calculations — like, run down through a decision tree or perform the math encoded by a neural network — so that the score is then immediately available to the operational system.
By the way, here’s a fun example of a deployed predictive model: the game 20Q, an inexpensive toy the size and shape of a yoyo.

It asks you 20 yes/no questions and tries to guess the thing you’re thinking of, like any physical object like a nail clipper or whatever. This toy has a deployed neural network — not a decision tree, actually — since a neural network model is more robust against errors. Like, if you wrongly answer one of the questions, it may still guess correctly. And, besides, some of the questions are subjective, like, “Does it make you happy?” You can try playing it without buying one right on their website at www.20q.net.
The post Liftoff: The Basics of Predictive Model Deployment appeared first on Predictive Analytics World.
]]>The post Hot Video: More Accuracy Fallacies – Predicting Criminality and Psychosis appeared first on Predictive Analytics World.
]]>Check out this topical video from Predictive Analytics World founder Eric Siegel:
Can AI “tell” if you’re a criminal? Or whether you’ll develop psychosis? These are perfect examples of the accuracy fallacy, which misleads the public into believing that machine learning can distinguish between positive and negative cases and usually be right about it.
The post Hot Video: More Accuracy Fallacies – Predicting Criminality and Psychosis appeared first on Predictive Analytics World.
]]>The post The Precondition for Machine Learning Success: Bridge the Quant/Business Culture Gap appeared first on Predictive Analytics World.
]]>
By: Eric Siegel, Predictive Analytics World
Over the last few years, I poured thousands of working hours and 25 years of consulting and teaching experience into making the online course Machine Learning Leadership and Practice – End-to-End Mastery.
Why? I developed this training program because teaching is in my blood and I was dying to fulfill two unmet training requirements:
1) A comprehensive, accessible go-to for business professionals that empowers them to generate business value with machine learning
2) A must-take for everyone involved with machine learning (both techies and business leaders) that uniquely supplements technical machine learning courses by covering critical material that’s normally skipped over
What critical material do ML courses normally skip over? Two main things. The business-side best practices – including a very particular leadership process. And a business-oriented, lay-friendly dive into the core tech that’s understandable even to learners without a technical background – including how it works, how well it needs to work, and why it often doesn’t work.
Now, one thing’s for sure: ML is booming. It reinvents industries and runs the world. According to the Harvard Business Review, ML is “the most important general-purpose technology of our era.”
But ML presents a great challenge for its business-side leadership: It requires an in-depth business-side understanding of how to position and deploy this technology, as well as a very particular business leadership process. That is to say that, to use ML, you need both business leadership and data science – and both sides need to learn both sides in order to successfully collaborate, jointly plan, and jointly execute.
The most common mistake that derails ML projects is to jump into the ML itself, the actual number crunching, before establishing a path to operational deployment. ML isn’t a technology you simply buy and plug in. Rather, you’re embarking upon a new kind of value proposition, and so it requires a new kind of leadership process.
The real-world use of ML far transcends its core number crunching. Think of ML not as a technology but as an organizational paradigm that leads to improved business operations. To follow this paradigm, you’ve got to bridge what is a prevalent gap between business leadership and technical know-how. You must bridge this quant/business cultural divide by way of a wholly collaborative process guided jointly by strategic, operational, and analytical stakeholders.
That is to say that, for ML to deliver value, two different “species” must cooperate in harmony: the business leader and the quant. In order to function together, they each have to adapt. On the one hand, the quant needs to attain a business-oriented vantage. And on the other, the business leader must navigate a very alien world.
Bridging this gargantuan divide is worth the effort. If you construct a durable bridge across that gap, you can achieve the value of ML deployment. Applying the core algorithms – which learn from data to predict – is only half of the trick. Beyond the technical process, there’s an organizational process. Since existing business operations must change by way of implementing analytics, it’s no longer business as usual. Science now drives your enterprise’s greatest pipelines of decisions and actions. In this way, deploying ML is intrinsically revolutionary.
So you must precisely plan for how it’s going to be deployed. For each initiative, you’ve gotta clear a path – from the get-go – that will lead to machine learning’s integration. This requires a socialization of buy-in: Line of business leaders and managers must agree to make a real change to operations. To that end, they must learn what the predictions generated by ML do for them and they must be willing to put their faith in them.
Now, the entire ML industry is compromised because, the thing is, this often doesn’t work out. As they say… well, as Hulya Farinas put it, “At companies where there is no framework for the operationalization of models, PowerPoint is where [predictive] models go to die!”
But organizations that follow best practices in ML leadership thrive.
So, whether you’ll participate on the business or tech side of a ML project, the business-side fundamentals of ML make for essential, pertinent know-how. They’re needed in order to ensure the core technology works within – and successfully produces value for – business operations.
To dive in, I invite you – and your team – to take my Machine Learning Leadership and Practice – End-to-End Mastery.
Those who are more a quant than a business leader will find this curriculum to be a rare opportunity to ramp up on the business side, since technical ML trainings don’t usually go there. Data wonks must know this: The soft skills are often the hard ones.
See also this article: Machine Learning’s Missing Link: Business Leadership
The post The Precondition for Machine Learning Success: Bridge the Quant/Business Culture Gap appeared first on Predictive Analytics World.
]]>The post Hot Video: The Accuracy Fallacy – Bogus Machine Learning Results appeared first on Predictive Analytics World.
]]>Check out this topical video from Predictive Analytics World founder Eric Siegel:
Can AI “tell” if you’re gay? When machine learning practitioners claim their model achieves “high accuracy,” it’s often bogus. This video reveals the undeniable yet common “accuracy fallacy”.
The post Hot Video: The Accuracy Fallacy – Bogus Machine Learning Results appeared first on Predictive Analytics World.
]]>The post Explainable Machine Learning, Model Transparency, and the Right to Explanation appeared first on Predictive Analytics World.
]]>Check out this topical video from Predictive Analytics World founder Eric Siegel:
A computer can keep you in jail, or deny you a job, a loan, insurance coverage, or housing – and yet you cannot face your accuser. The predictive models generated by machine learning to drive these weighty decisions are generally kept locked up as a secret, unavailable for audit, inspection, or interrogation. The video above covers explainable machine learning and the loudly-advocated machine learning standards transparency and the right to explanation. Eric discusses why these standards generally are not met and overviews the policy hurdles and technical challenges that are holding us back.
The post Explainable Machine Learning, Model Transparency, and the Right to Explanation appeared first on Predictive Analytics World.
]]>The post Machine Learning’s Missing Link: Business Leadership appeared first on Predictive Analytics World.
]]>
Machine learning. Your team needs it, your boss demands it, and your career loves it. After all, LinkedIn places it as one of the top few “Skills Companies Need Most” and as the very top emerging job in the U.S.
But this number-crunching craze tends to, tragically, overlook one key point: Of all the ingredients that are key to success with machine learning, the one that’s most often missing isn’t about technology or data. It’s about leadership. Many business leaders do know that machine learning can’t succeed in optimizing operations without a proven management process guiding the project – but data scientists tend to focus on one thing and one thing only: the hands-on practice of analytics.
Now, it’s true that you learn best from doing – but the number crunching is only half of what needs to get done. There’s also a business-side leadership process critical to machine learning’s value-driven deployment, and data scientists must ramp up on it just as well as business leaders. Whether you’ll participate on the business or tech side of a machine learning project, the business-side skills of ML are essential, pertinent know-how. They’re needed in order to ensure the core technology works within – and successfully produces value for – business operations.
A main, central portion of my course “Machine Learning Leadership and Practice – End-to-End Mastery” addresses this need. First, allow me to tell you about the course: It will guide you and your team to lead or participate in the end-to-end implementation of machine learning. It’s an expansive curriculum that’s accessible to business-level learners and yet vital to techies as well. It covers both the state-of-the-art techniques and the business-side best practices.
By covering the business-side requirements, unlike most machine learning courses, this one prepares you to avoid the most common management mistake that derails machine learning projects: jumping straight into the number crunching before establishing and planning for a path to operational deployment.
In particular, the course includes three sub-courses, one entitled, “Launching Machine Learning: Delivering Operational Success with Gold Standard ML Leadership”, which focuses entirely on the business side. After this sub-course, you will be able to:
– Lead ML: Manage a machine learning project, from the generation of predictive models to their launch.
– Apply ML: Identify the opportunities where machine learning can improve marketing, sales, financial credit scoring, insurance, fraud detection, and much more.
– Plan ML: Determine the way in which machine learning will be operationally integrated and deployed, and the staffing and data requirements to get there.
– Greenlight ML: Forecast the effectiveness of a machine learning project and then internally sell it, gaining buy-in from your colleagues.
– Prep data for ML: Oversee the data preparation, which is directly informed by business priorities.
– Evaluate ML: Report on the performance of predictive models in business terms, such as profit and ROI.
– Regulate ML: Manage ethical pitfalls, such as when predictive models reveal sensitive information about individuals, including whether they’re pregnant, will quit their job, or may be arrested.
The first module of this sub-course dives deeply into the business applications of machine learning – for marketing, financial services, fraud detection and more. We illustrate the value delivered for these domains by way of case studies and detailed examples. And we’ll precisely measure the performance of the predictive models themselves, focusing on model lift, a predictive multiplier that tells you the improvement achieved by a model.
The second module of this sub-course covers scoping, greenlighting, and managing machine learning initiatives. Launching machine learning is as much a management endeavor as a technical one – its success relies on a very particular business leadership practice. This module will demonstrate that practice, guiding you to lead the end-to-end implementation of machine learning. Here’s its outline of topics:
Leadership process: How to manage machine learning projects
- Project management overview
- The six steps for running a ML project
- Running and iterating on the process steps
- How long a machine learning project takes
- Refining the prediction goal
Project scoping and greenlighting
- Where to start – picking your first ML project
- Strategic objectives and key performance indicators
- Personnel – staffing your machine learning team
- Sourcing the staff for a machine learning project
- Greenlighting: Internally selling a machine learning initiative
- More tips for getting the green light
And finally, the third module of this sub-course covers the data requirements – which needs very much to be informed by business-side considerations – and the fourth and last module covers more business metrics – including a fallacy about “high-accuracy” machine learning that spreads misinformation all across the Internet – and tackles some critical, alarming topics in machine learning ethics.
Those who are more a hands-on technical quant than a business leader will find this curriculum to be a rare opportunity to ramp up on the business side, since technical machine learning trainings don’t usually go there. But data wonks must know this: The soft skills are often the hard ones.
To learn more, check out the details of “Machine Learning Leadership and Practice – End-to-End Mastery.”
About the Author
 Eric Siegel, Ph.D., is a leading consultant and former Columbia University professor who makes machine learning understandable and captivating. He is the founder of the Predictive Analytics World and Deep Learning World conference series, which have served more than 17,000 attendees since 2009, the instructor of the acclaimed online course “Machine Learning Leadership and Practice – End-to-End Mastery”, a popular speaker who’s been commissioned for more than 110 keynote addresses, and executive editor of The Machine Learning Times. He authored the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, which has been used in courses at more than 35 universities, and he won teaching awards when he was a professor at Columbia University, where he sang educational songs to his students. Eric also publishes op-eds on analytics and social justice. Follow him at @predictanalytic.
Eric Siegel, Ph.D., is a leading consultant and former Columbia University professor who makes machine learning understandable and captivating. He is the founder of the Predictive Analytics World and Deep Learning World conference series, which have served more than 17,000 attendees since 2009, the instructor of the acclaimed online course “Machine Learning Leadership and Practice – End-to-End Mastery”, a popular speaker who’s been commissioned for more than 110 keynote addresses, and executive editor of The Machine Learning Times. He authored the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, which has been used in courses at more than 35 universities, and he won teaching awards when he was a professor at Columbia University, where he sang educational songs to his students. Eric also publishes op-eds on analytics and social justice. Follow him at @predictanalytic.
The post Machine Learning’s Missing Link: Business Leadership appeared first on Predictive Analytics World.
]]>The post Six Ways Machine Learning Threatens Social Justice appeared first on Predictive Analytics World.
]]>
Originally published in Big Think
When you harness the power and potential of machine learning, there are also some drastic downsides that you’ve got to manage. Deploying machine learning, you face the risk that it be discriminatory, biased, inequitable, exploitative, or opaque. In this article, I cover six ways that machine learning threatens social justice – linking to short videos that dive deeply into each one – and reach an incisive conclusion: The remedy is to take on machine learning standardization as a form of social activism.
When you use machine learning, you aren’t just optimizing models and streamlining business. You’re governing. In essence, the models embody policies that control access to opportunities and resources for many people. They drive consequential decisions as to whom to investigate, incarcerate, set up on a date, or medicate – or to whom to grant a loan, insurance coverage, housing, or a job.
For the same reason that machine learning is valuable – that it drives operational decisions more effectively – it also wields power in the impact it has on millions of individuals’ lives. Threats to social justice arise when that impact is detrimental, when models systematically limit the opportunities of underprivileged or protected groups.
Here are six ways machine learning threatens social justice:
For each threat, follow the link(s) to view short videos that provide a deep dive. Most videos are from Machine Learning for Everyone, my course series on Coursera, which is also free to access in its entirety.
1) Blatantly discriminatory models are predictive models that base decisions partly or entirely on a protected class. Protected classes include race, religion, national origin, gender, gender identity, sexual orientation, pregnancy, and disability status. By taking one of these characteristics as an input, the model’s outputs – and the decisions driven by the model – are based at least in part on membership in a protected class. Although models rarely do so directly, there is precedent and support for doing so.
This would mean that a model could explicitly hinder, for example, black defendants for being black. So, imagine sitting across from a person being evaluated for a job, a loan, or even parole. When they ask you how the decision process works, you inform them, “For one thing, our algorithm penalized your score by seven points because you’re black.” This may sound shocking and sensationalistic, but I’m only literally describing what the model would do, mechanically, if race were permitted as a model input. [Deep dive videos: part I, part II, part III]
2) Machine bias. Even when protected classes are not provided as a direct model input, we find, in some cases, that model predictions are still inequitable. This is because other variables end up serving as proxies to protected classes. This is a bit complicated, since it turns out that models that are fair in one sense are unfair in another.
For example, some crime risk models succeed in flagging both black and white defendants with equal precision – each flag tells the same probabilistic story, regardless of race – and yet the models falsely flag black defendants more often than white ones. A crime-risk model called COMPAS, which is sold to law enforcement across the US, falsely flags white defendants at a rate of 23.5%, and black defendants at 44.9%. In other words, black defendants who don’t deserve it are erroneously flagged almost twice as much as white defendants who don’t deserve it. [Deep dive videos: part I, part II, part III]
3) Inferring sensitive attributes – predicting pregnancy and beyond. Machine learning predicts sensitive information about individuals, such as sexual orientation, whether they’re pregnant, whether they’ll quit their job, and whether they’re going to die. Researchers have shown that it is possible to predict race based on Facebook likes. These predictive models deliver dynamite.
In a particularly extraordinary case, officials in China use facial recognition to identify and track the Uighurs, a minority ethnic group systematically oppressed by the government. This is the first known case of a government using machine learning to profile by ethnicity. One Chinese start-up valued at more than $1 billion said its software could recognize “sensitive groups of people.” It’s website said, “If originally one Uighur lives in a neighborhood, and within 20 days six Uighurs appear, it immediately sends alarms” to law enforcement. [Deep dive video]
4) A lack of transparency. A computer can keep you in jail, or deny you a job, a loan, insurance coverage, or housing – and yet you cannot face your accuser. The predictive models generated by machine learning to drive these weighty decisions are generally kept locked up as a secret, unavailable for audit, inspection, or interrogation. Such models, inaccessible to the public, perpetrate a lack of due process and a lack of accountability.
Two ethical standards oppose this shrouding of electronically-assisted decisions: 1) model transparency, the standard that predictive models be accessible, inspectable, and understandable. And 2) the right to explanation, the standard that consequential decisions that are driven or informed by a predictive model are always held up to that standard of transparency. Meeting those standards would mean, for example, that a defendant be told which factors contributed to their crime risk score — which aspects of their background, circumstances, or past behavior caused the defendant to be penalized. This would provide the defendant the opportunity to respond accordingly, establishing context, explanations, or perspective on these factors. [Deep dive video on transparency, explainable machine learning, and “the right to explanation”]
5) Predatory micro-targeting. Powerlessness begets powerlessness – and that cycle can magnify for consumers when machine learning increases the efficiency of activities designed to maximize profit for companies. Improving the micro-targeting of marketing and the predictive pricing of insurance and credit can magnify the cycle of poverty. For example, highly-targeted ads are more adept than ever at exploiting vulnerable consumers and separating them from their money.
And insurance pricing can lead to the same result. With insurance, the name of the game is to charge more for those at higher risk. Left unchecked, this process can quickly slip into predatory pricing. For example, a churn model may find that elderly policyholders don’t tend to shop around and defect to better offers, so there’s less of an incentive to keep their policy premiums in check. And pricing premiums based on other life factors also contributes to a cycle of poverty. For example, individuals with poor credit ratings are charged more for car insurance. In fact, a low credit score can increase your premium more than an at-fault car accident. [Deep dive video]
6) The coded gaze. If a group of people is underrepresented in the data from which the machine learns, the resulting model won’t work as well for members of that group. This results in exclusionary experiences and discriminatory practices. This phenomenon can occur for both facial image processing and speech recognition. [Deep dive video]
Recourse: Establish machine learning standards as a form of social activism
To address these problems, take on machine learning standardization as a form of social activism. We must establish standards that go beyond nice-sounding yet vague platitudes such as “be fair”, “avoid bias”, and “ensure accountability”. Without being precisely defined, these catch phrases are subjective and do little to guide concrete action. Unfortunately, such broad language is fairly common among the principles released by many companies. In so doing, companies protect their public image more than they protect the public.
Your role is critical. As someone involved in initiatives to deploy machine learning, you have a powerful, influential voice – quite possibly much more important and powerful than you realize. You are one of a relatively small number of people who mold and set the trajectory for systems that automatically dictate the rights and resources that great numbers of consumers and citizens gain access to. You’re in a unique position to defend the civil rights of hundreds of thousands or millions of people and therefore, I would say, you have a unique responsibility to do so.
Famed machine learning leader and educator Andrew Ng drove it home: “AI is a superpower that enables a small team to affect a huge number of people’s lives… It’s important that you… make sure the work you do leaves society better off.”
And Allan Sammy, Director, Data Science and Audit Analytics at Canada Post, clarified why the onus is on you: “A decision made by an organization’s analytic model is a decision made by that entity’s senior management team.”
Implementing ethical data science is as important as ensuring a self-driving car knows when to put on the breaks.
Establishing well-formed ethical standards for machine learning will be an intensive, ongoing process. For more, watch this short video, in which I provide some specifics meant to kick-start the process.
About the Author
Eric Siegel, Ph.D., is a leading consultant and former Columbia University professor who makes machine learning understandable and captivating. He is the founder of the long-running Predictive Analytics World and the Deep Learning World conference series, which have served more than 17,000 attendees since 2009, the instructor of the end-to-end, business-oriented Coursera specialization Machine learning for Everyone, a popular speaker who’s been commissioned for more than 100 keynote addresses, and executive editor of The Machine Learning Times. He authored the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, which has been used in courses at more than 35 universities, and he won teaching awards when he was a professor at Columbia University, where he sang educational songs to his students. Eric also publishes op-eds on analytics and social justice.
The post Six Ways Machine Learning Threatens Social Justice appeared first on Predictive Analytics World.
]]>The post Coursera’s “Machine Learning for Everyone” Fulfills Unmet Training Requirements appeared first on Predictive Analytics World.
]]>
My new course series on Coursera, Machine Learning for Everyone (free access), fulfills two different kinds of unmet learner needs. It’s a conceptually-complete, end-to-end course series – its three courses amount to the equivalent of a college or graduate-level course – that covers both the technology side and the business side. While fully accessible and understandable to business-level learners, it’s also also vital to data scientists and budding technical practitioners, since it covers:
- The state-of-the-art techniques
- The business leadership best practices
- A wide range of common pitfalls and how to avoid them
1) A comprehensive go-to for BUSINESS-SIDE learners – by covering the following:
- ML project leadership (management process)
- ML algorithms: substantive yet accessible coverage
- Data preparation
2) Need-to-knows for EVERYONE in ML – both business-side learners and technical practitioners – by also covering the following:
- ML ethics: risks to social justice, equitable models, machine bias, etc.
- Business-oriented performance metrics
- Uplift modeling (aka persuasion modeling)
- Major pitfalls, in-depth:
- P-hacking
- Overfitting
- The accuracy fallacy
- Presuming causation from correlations
- Serious problems with hyping ML as “AI”
This checklist illustrates the unique contribution of this curriculum:

More information about “Machine Learning for Everyone”:
Brief curriculum overview (video)
Seven Reasons Budding Data Scientists Need a Machine Learning Course That’s Not Hands-On
Geek Stuns World with Machine Learning Rap Music Video
Opening video: How Machine Learning Works – in 20 Seconds
Watch 3 Videos from Coursera’s New “Machine Learning for Everyone”
About the Author
 Eric Siegel, Ph.D., is a leading consultant and former Columbia University professor who makes machine learning understandable and captivating. He is the founder of the long-running Predictive Analytics World and the Deep Learning World conference series, which have served more than 17,000 attendees since 2009, the instructor of the end-to-end, business-oriented Coursera specialization “Machine learning for Everyone”, a popular speaker who’s been commissioned for more than 100 keynote addresses, and executive editor of The Machine Learning Times. He authored the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, which has been used in courses at more than 35 universities, and he won teaching awards when he was a professor at Columbia University, where he sang educational songs to his students. Eric also publishes op-eds on analytics and social justice.
Eric Siegel, Ph.D., is a leading consultant and former Columbia University professor who makes machine learning understandable and captivating. He is the founder of the long-running Predictive Analytics World and the Deep Learning World conference series, which have served more than 17,000 attendees since 2009, the instructor of the end-to-end, business-oriented Coursera specialization “Machine learning for Everyone”, a popular speaker who’s been commissioned for more than 100 keynote addresses, and executive editor of The Machine Learning Times. He authored the bestselling Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die, which has been used in courses at more than 35 universities, and he won teaching awards when he was a professor at Columbia University, where he sang educational songs to his students. Eric also publishes op-eds on analytics and social justice.
The post Coursera’s “Machine Learning for Everyone” Fulfills Unmet Training Requirements appeared first on Predictive Analytics World.
]]>The post How Machine Learning Works – in 20 Seconds appeared first on Predictive Analytics World.
]]>This transcript comes from Coursera’s online course series, Machine Learning for Everyone with Eric Siegel.
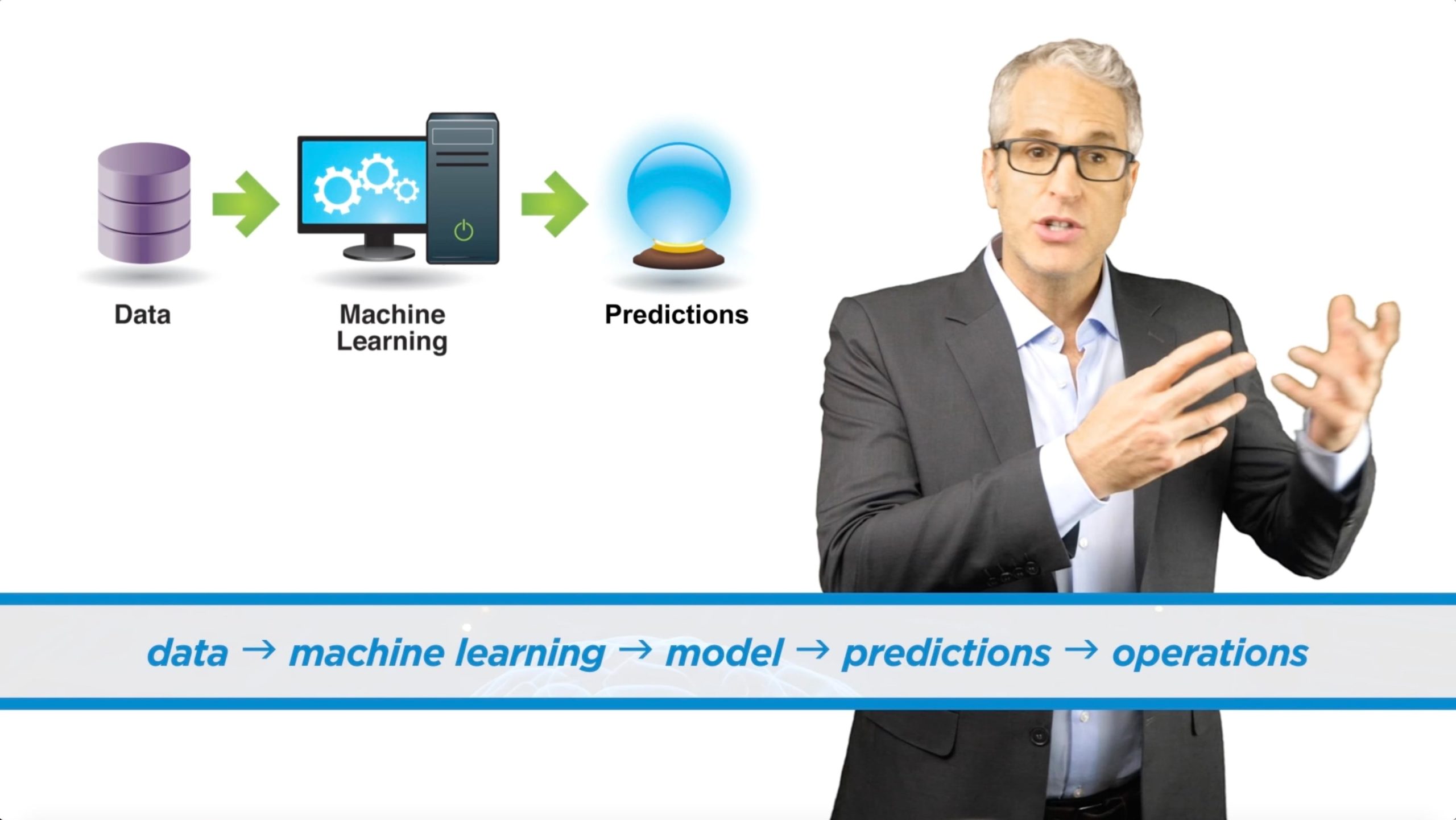
In 57 words, here’s why machine learning’s important: Business needs prediction. Prediction requires machine learning. And machine learning depends on data. Putting that in reverse, we have data, we give it to machine learning, it makes models that predict, and we use the predictions to improve all the main stuff we do, all the large-scale operations of organizations that make the world go ’round.
data → machine learning → model → predictions → operations
In this article, I’ll run through these five concepts to show you how learning from data to predict revolutionizes business and I’ll make the case that machine learning is the coolest and most interesting science, period. And then, in the next piece, I’ll reveal why this specialization of three courses is a unique, effective way to get started with machine learning.
Ok, here’s the opportunity: The world is a remarkably inefficient, wasteful place. The organizations that treat and serve us as consumers constantly get it wrong. Most mail is junk mail. Institutions are blindsided by risky debtors and policyholders. Lot’s of fraud goes undetected and yet most of the transactions humans bother to audit are legit and don’t actually need auditing. In healthcare research, we typically show that a treatment works in general, but we can’t discern which patients would actually be better off untreated.
These are heavy costs that tax both you and I every day. If only there were some way to run things better, to do a better job making all these decisions, to improve the effectiveness of the frontline operations that define a functional society. Well, I just happen to have a suggestion.
Prediction as a capability is the Holy Grail for driving decisions such as whom to target for marketing, for investigation, or for protection from financial or medical risk. Now, perfect prediction is not possible, but even lousy predictions that are at least better than guessing often deliver a tremendous systematic benefit. Playing these numbers games better, tipping the odds even just a bit more in our favor, generates an enormous impact.
And this is where the idea of learning comes in. It learns to predict. Kinda like what people do — I’m drawing an analogy — an organization learns from its overall cumulative experience when its computer learns from its data. The data’s a record of things that have happened, the aggregate experience. Advanced number crunching methods that discover patterns in the data are what we call machine learning.
That learning process makes it possible to predict — to put odds on behaviors and outcomes, such as whether a customer will click, buy, lie, or die. In fact, every important thing a person does can be valuable to predict, including: consume, work, quit, vote, love, procreate, divorce, default on credit payments, cheat, steal, or kill.
The predictions from machine learning drive millions of decisions more effectively, determining whom to call, mail, approve, test, diagnose, warn, investigate, incarcerate, set up on a date, or medicate. Improving these many decisions even just a bit delivers a huge win.
And prediction’s not the only capability. Computers also learn to identify objects in images — which is key for self-driving cars, smart manufacturing, medical image processing, and even Facebook’s suggestions for tagging photos — and they learn to identify words within sound for speech recognition. These capabilities have made leaps and bounds in recent years, mostly due to a specific machine learning method called deep learning.
So, by the way, machine learning lives at the center of “artificial intelligence,” and so this is very much an AI course. But, AI really is just a nifty story, not a well-defined technology. Often, when people say AI, they actually just mean machine learning.
Anyway, the outlook for machine learning is better than ever because… it’s raining data. Every credit card transaction, Facebook post, medical diagnosis, car accident, and sales call is recorded. Data grows by an estimated 2.5 quintillion bytes per day. It’s the most potent “unnatural resource.” Today’s totally historical advent of having data about everything and using data for everything is a profound game changer.
Now, data does seem boring to some people. If so, I’d argue, you’re not geeky enough. I’ll change your mind by showing you that data isn’t arcane — after all, it’s actually a long list of things that have happened — and I’ll show you that the discoveries from data make actual sense, like sometimes even in the form of if-then business rules.
And besides, it’s freakin’ cool! When you unleash the power of data in this way, you’re making the ultimate use of these amazing general-purpose machines that we know as computers, using them for the most all-encompassing of tasks, which is: getting better at tasks — that is, learning. The algorithms to do this take on the most transcendental kind of scientific challenge: to generalize from examples and discern truths that hold in this world.
Beyond a field of science, machine learning is a movement that’s exerting a forceful impact. It reinvents industries and runs the world. It’s come of age as a pervasive business practice necessary to thrive and even just survive. Companies, governments, law enforcement, and hospitals seize upon this power to boost sales, cut costs, combat risk, prevent fraud, fortify healthcare, streamline manufacturing, conquer spam, toughen crime fighting, and win elections.
Your team needs it, your boss demands it, and your career loves machine learning. After all, it’s consistently ranked as a top in-demand skill and LinkedIn places it as the very top emerging job in the U.S.
Coursera co-founder Andrew Ng calls machine learning “the new electricity,” and The Harvard Business Review calls it “The most important general-purpose technology of our era.”
I would like to hereby designate machine learning the most fascinating, promising, and exciting branch of science and technology, period. It’s the coolest.
This is a transcript from Coursera’s online course series, Machine Learning for Everyone.This end-to-end, three-course series will empower you to launch machine learning. Accessible to business-level learners and yet vital to techies as well, it covers both the state-of-the-art techniques and the business-side best practices. Enroll and access the entire curriculum at no cost.
The post How Machine Learning Works – in 20 Seconds appeared first on Predictive Analytics World.
]]>